本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
やったこと
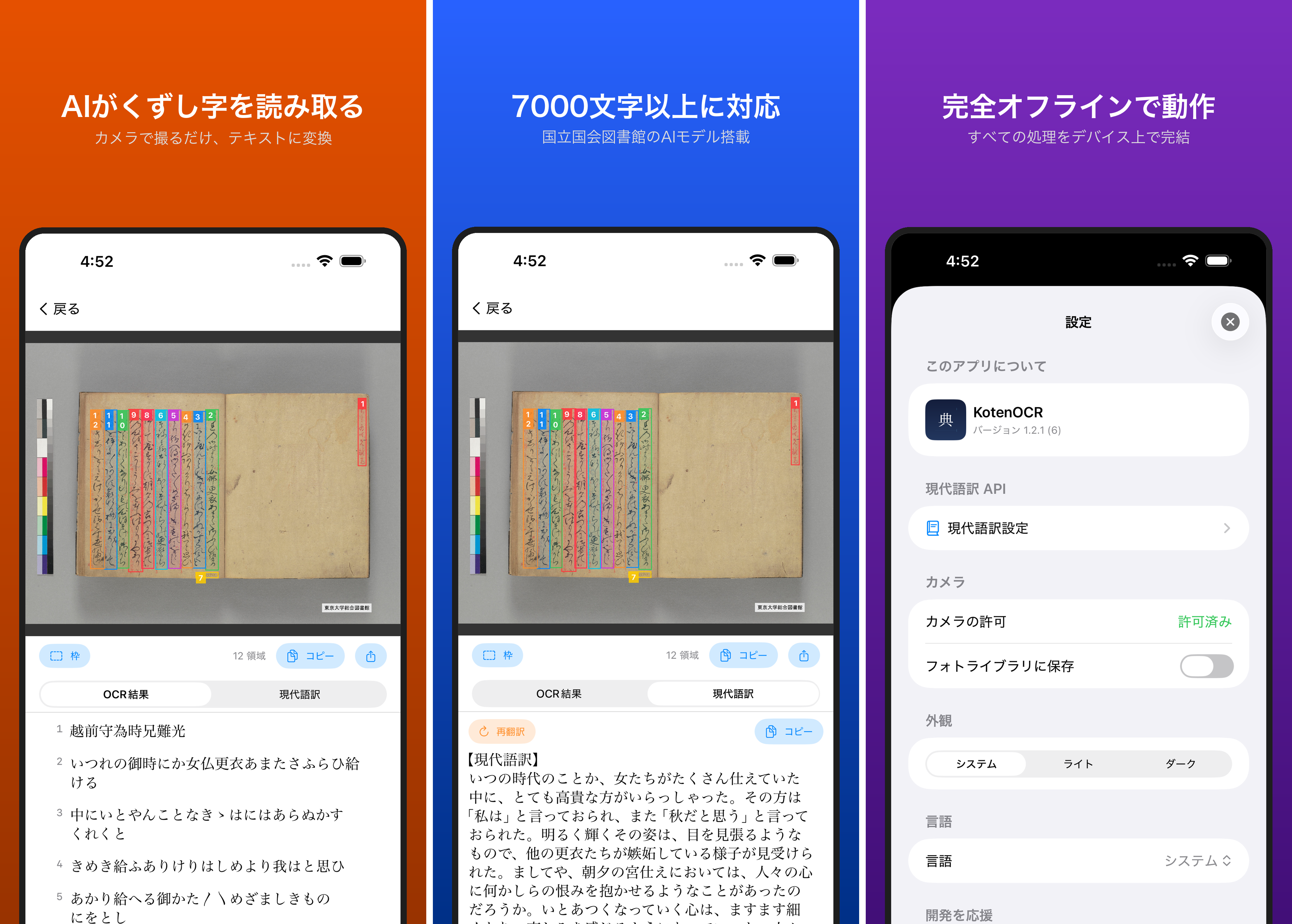
くずし字・古文書の画像処理をこれまで Python(Gradio の Hugging Face Space)で動かしていましたが、これを Python 非依存の JS/Node(onnxruntime-node)に移植してみた記録です。具体的には次の4本立てです。
- YOLOv11x の文字検出を ONNX 化して Next.js(API Route)でサーバ推論
- **NDL古典籍OCR-Lite の行検出(RTMDet)**を JS に移植
- int8 量子化して fp32 と精度・サイズ・速度を比較
- NDL OCR のコアを フレームワーク非依存ライブラリに切り出し
また、デプロイ先として Vercel(serverless)で動かすのは難しいことが分かったので、その理由も整理します(コンテナや Node サーバなら動きます)。
使ったモデルは nakamura196/yolov11x-codh-char(MIT、文字 bbox 検出)と、NDL古典籍OCR-Lite(CC BY 4.0、rtmdet-s の行検出+parseq の文字認識)です。
1. YOLOv11 → ONNX 変換
Ultralytics には ONNX export が組み込まれているので、変換自体は一行です。
from ultralytics import YOLO
m = YOLO("best.pt")
m.export(format="onnx", imgsz=1280, opset=12,
dynamic=True, # 入力 H/W を可変に(baseline=1280, SAHIタイル=1024 両対応)
simplify=True,
nms=False) # 後処理(NMS)は JS 側で実装するので付けない
確認できた仕様は次のとおりです。
- 入力
images [batch, 3, H, W]float32(RGB, /255, letterbox) - 出力
output0 [1, 5, N]=(cx, cy, w, h, score)× N アンカー(1クラス。imgsz=1280 で N=33600) - 精度劣化なし:
.ptと.onnxで検出ボックス数が一致(サンプル画像で 251 個)
注意点として、fp32 で書き出すと 元の .pt(109MB)の約2倍=217MB になります。これが後でデプロイのネックになります。
2. Next.js(onnxruntime-node)でサーバ推論
「UI は Next.js、推論はサーバの Node プロセス」という構成にしました。前処理(letterbox)・後処理(NMS)・SAHI(タイル分割)・読み順グルーピングはすべて TypeScript で実装し直します。
前処理:letterbox
ONNX の入力テンソルを作る部分。ブラウザでもサーバでも canvas で書けます。
const scale = imgsz / Math.max(W, H);
const newW = Math.round(W * scale), newH = Math.round(H * scale);
const padLeft = Math.floor((imgsz - newW) / 2);
const padTop = Math.floor((imgsz - newH) / 2);
const ctx = createCanvas(imgsz, imgsz).getContext("2d");
ctx.fillStyle = "rgb(114,114,114)"; // ultralytics の灰色パディング
ctx.fillRect(0, 0, imgsz, imgsz);
ctx.drawImage(src, padLeft, padTop, newW, newH);
const { data } = ctx.getImageData(0, 0, imgsz, imgsz); // RGBA
const plane = imgsz * imgsz;
const tensor = new Float32Array(3 * plane);
for (let i = 0; i < plane; i++) {
tensor[i] = data[i * 4] / 255; // R
tensor[plane + i] = data[i * 4 + 1] / 255; // G
tensor[2 * plane + i] = data[i * 4 + 2] / 255; // B
}
後処理は出力 [1,5,N] を走査し、score >= conf で絞って xywh→xyxy、letterbox を解除して元座標へ戻し、クラス非依存 NMS をかけるだけです。Python の挙動とほぼ一致しました(canvas のリサイズ補間が PIL と微妙に違うため 251→249 と数個ずれる程度)。
SAHI(タイル分割)
高解像度(縮小率 = 長辺/1280 が 2.0 超)では、画像をそのまま縮小すると小さな文字が潰れます。そこで 1024px のタイルに 20% オーバーラップで分割し、原寸近くで推論 → 元座標に戻してグローバル NMS、という SAHI 風の処理を実装しました。タイルは最大 1024 なので 推論サイズも 1024にすると、1280 へ無駄に拡大せずに済みます(6144×4096 の画像で 84 秒 → 58 秒に短縮)。
ハマりどころ:sharp が Node 25 で入らない
最初は画像処理に定番の sharp を使うつもりでしたが、Node 25.6 で npm install すると prebuilt を拾えずソースビルドに falし、失敗 → インストール全体がロールバックしました。これは npm が sharp の optional な platform 依存(@img/*)を入れない既知のバグで、sharp 自体が Node 25 非対応というわけではありません(後述のライブラリ側では同じ Node 25 で sharp が動いています)。
この Next.js 側では、画像処理を @napi-rs/canvas に切り替えて回避しました。N-API の prebuilt が堅牢で、しかも canvas はブラウザ標準と同じ API なので、前処理コードがほぼそのまま使えます。
実測(CPU):baseline は 2.3 秒、SAHI は 58 秒でした。
3. NDL古典籍OCR-Lite の行検出(RTMDet)を移植
文字 bbox とは別に、NDL の RTMDet による行/レイアウト検出も JS に移植しました。これがあると「行 bbox の表示」や「行領域の外に出た誤検出(定規・色見本など)の除去」ができます。
元の Python 実装を読み解いた要点:
- ファイル名は
rtmdet-s-1280x1280.onnxですが、実体の入力は 1024×1024(コードはモデルから読むので動いていた) - 出力は
dets [1,N,5]=(x1,y1,x2,y2,score)とlabels [1,N]、NMS はモデル内蔵(後処理はスコア閾値だけ) - 前処理は YOLO と違い、正方形に 黒パディング(左上寄せ)→ 1024 へ resize → RGB→BGR →
(px - mean) / std(mean/std は BGR 順)→ CHW
const MEAN = [103.53, 116.28, 123.675]; // BGR
const STD = [57.375, 57.12, 58.395];
// CHW, チャネル順は BGR
tensor[i] = (b - MEAN[0]) / STD[0];
tensor[plane + i] = (g - MEAN[1]) / STD[1];
tensor[2 * plane + i] = (r - MEAN[2]) / STD[2];
後処理でボックスを ÷1024 ×(正方パディングサイズ)で元座標に戻し、各ボックスを縦に 2% 拡張します。Python の参照実装と照合したところ、行数 16〜17 本・座標は約 2px 差で一致しました。前処理(BGR・mean/std・パディング・スケール戻し)が正しく移植できている証拠です。
4. int8 量子化と精度比較
217MB は大きいので int8 量子化を試し、fp32 と比較しました。結論から言うと quantize_dynamic + QUInt8 を使うべきで、それ以外はうまくいきませんでした。
| 方式 | weight_type | 結果 |
|---|---|---|
quantize_dynamic | QUInt8 | ✅ 採用 |
quantize_dynamic | QInt8 | ❌ ロード不能(ConvInteger(opset10) が ORT 1.23 CPU で NOT_IMPLEMENTED) |
quantize_static(per-channel) | QInt8 | ❌ 検出 0 件で壊滅 / QDQ は invalid graph |
QUInt8 dynamic での比較(fp32 を正解、IoU≥0.5、CPU、各画像5回の中央値):
| 画像 | fp32 box | int8 box | F1 | recall | mIoU | t_fp32 | t_int8 |
|---|---|---|---|---|---|---|---|
| 竹取物語(版本) | 251 | 250 | 0.990 | 0.988 | 0.959 | 2.35s | 0.99s |
| 伊藤博文書簡(書状) | 546 | 536 | 0.969 | 0.960 | 0.964 | 2.95s | 1.15s |
| 東寺百合文書(古文書) | 319 | 252 | 0.862 | 0.771 | 0.963 | 2.47s | 1.79s |
全体では サイズ 228→58MB(3.9倍圧縮)、CPU 推論 2.15 倍高速、F1 0.945、conf 誤差 0.048。
注目すべきは、古文書だけ recall が 0.771 に落ちる点です(319→252、低信頼度の文字を取りこぼす)。マッチしたボックスの IoU は 0.96 と高いので「位置ズレ」ではなく「拾い漏れ」です。版本や近代の書状では int8 でほぼ問題ありませんが、くずし字の古文書で再現率が効く用途では fp32 を残すのが無難、という実用的な結論になりました。
5. デプロイ:Vercel(serverless)で動かすのは難しい
デプロイ先として Vercel に載せようとしたところ、serverless の制約に引っかかることが分かりました。
Vercel の Serverless Function には 250MB(unzipped)のサイズ上限があり、
best.onnx(fp32)だけで 217MB → モデル単体で上限にほぼ到達onnxruntime-nodeはパッケージに全 OS 分のバイナリを同梱していて 254MB(linux ネイティブだけなら ~36MB だが、ファイルトレースが落としきれず超過しがち)- さらに実行時間:SAHI は 58 秒で、Vercel の
maxDuration(Hobby 最大 60 秒 / Pro 300 秒)にぶつかる - ステートレスなのでコールドスタートのたびに数十〜200MB のモデルをロード
…と、Vercel の serverless としては実用になりません。int8(58MB)にしてもサイズが上限ギリギリで脆く、SAHI の実行時間問題も残ります。
一方で、next build && next start を コンテナや普通の Node サーバ(Fly.io / Render / Cloud Run / VPS など)で動かせば、217MB のモデルも onnxruntime-node も問題なく動きます。難しいのはあくまで Vercel の serverless 環境で動かすことで、ホスティングを選べば回避できる、という整理になりました。
WASM(onnxruntime-web)はどうか
ブラウザ完結も検討しました。コードは軽いです——モデルはすでに ONNX で、前処理・後処理の TS コードはそのまま流用でき、canvas はブラウザ標準。onnxruntime-web の API も onnxruntime-node とほぼ同じ。
大変なのは速度とサイズです。WASM CPU だと YOLO11x は重く、baseline 1 回でも数秒〜十数秒、SAHI(数十タイル)は数分かかり実質不可。WebGPU バックエンドなら baseline は 1〜3 秒まで来て実用圏ですが、対応ブラウザ依存。さらにマルチスレッドには COOP/COEP(cross-origin isolation)が要ります。モデルも int8 で 58MB を初回ダウンロードします。「baseline だけブラウザ完結デモ」なら現実的、というのが落としどころでした。
6. コアをライブラリに切り出す
実は NDL古典籍OCR のフル JS 実装(RTMDet 行検出 + PARSeq 文字認識 + XY-cut 読み順 + ALTO/NDL XML 出力)は、別途作っていた Tropy プラグインにすでにありました。上の Next.js 側で RTMDet を二重に書いてしまっていたので、コアを共有ライブラリに切り出すことにしました。
幸いコアは engine.recognize(sharpImage) → { blocks, lines, text } というフレームワーク非依存な形に分離されていたので、抽出はスムーズでした。
- 新パッケージ
@nakamura196/ndl-koten-ocr(独立リポジトリ) src/:engine / rtmdet / parseq / ndl-parser / xy-cut / alto / buffer-to-input- 設定 yaml は同梱、モデル(.onnx)は gitignore で symlink 運用
- Tropy プラグイン側は
file:../ndl-koten-ocrのローカル連携で依存 - テスト:ライブラリ 81 件 / Tropy 51 件、いずれも green
再掲:sharp インストールの確実な回避手順
ライブラリ側は Tropy に合わせて sharp を使います。例の npm optional 依存バグが出たときは、次の順で確実に入りました。
npm install --ignore-scripts
npm install --no-save --ignore-scripts @img/sharp-darwin-arm64@0.34.5 @img/sharp-libvips-darwin-arm64@1.2.4
--ignore-scripts で sharp のビルド失敗によるロールバックを防ぎ、prebuilt(@img/*)を明示追加する、という流れです(バージョンは sharp 本体に合わせる)。
まとめ
- YOLOv11 → ONNX は一行で、精度劣化もなし
- JS への移植は前処理/後処理(letterbox・NMS・SAHI・読み順・RTMDet)を素直に書き直せばよく、Python 参照と座標レベルで一致できた
- int8 量子化は
QUInt8dynamic 一択。3.9 倍圧縮・2 倍高速だが、古文書では recall が落ちるので本番は用途次第で fp32 - デプロイは Vercel(serverless)で動かすのが難しいことが分かった(サイズ・実行時間の制約)。コンテナや Node サーバなら動く
- WASM はコードは軽いが速度がネック。baseline は WebGPU で実用圏、SAHI は非現実的
- 重複実装を避けるため、NDL OCR コアは共有ライブラリ化した
「Python の重い OCR/検出パイプラインを、どこまで JS だけで・どこに置いて動かすか」を一通り試した記録でした。同じくくずし字・古典籍まわりで JS 移植を考えている方の参考になれば幸いです。

コメント
…