本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
デジタルアーカイブ向けの画像アノテーションツール IMMARKUS(React + Vite + TypeScript のオープンソースソフトウェア、以下 OSS)に、UI の国際化(internationalization、以下 i18n)レイヤーを追加し、日本語を最初の非英語ロケールとして実装しました。対象は全ページ(start / annotate / images / knowledge graph / data model / export / settings / about / X-MARKUS)と共有コンポーネントで、最終的に 13 namespace・各言語あたり 718 キーになりました。作業は 7 本の Pull Request(以下 PR)に分けてマージされています。
実装の結果は、まず画面で見るのが早いと思います。同じ start ページの英語版と日本語版です。
 英語表示。右上に言語スイッチャー(English)があります
英語表示。右上に言語スイッチャー(English)があります
 日本語に切り替えた状態。スイッチャーの選択肢を
日本語に切り替えた状態。スイッチャーの選択肢を 日本語 にすると UI 全体が切り替わります
この記事では、フレームワーク選定と namespace 設計、文字列の抽出、複数形やリンクを含む文の扱い、テストが無いリポジトリへの vitest + Playwright 導入、そしてページ単位で PR を分割したときに踏んだ点を、順にまとめます。「成熟した OSS の UI を後から i18n 化する」ときに参考になりそうな内容を中心にしています。
対象アプリと、後付け i18n の進め方
IMMARKUS はそれなりに成熟したコードベースで、UI 文字列が JSX の中に英語で直書きされていました。新規プロジェクトなら最初から t('...') で書けますが、後から i18n を入れる場合は事情が違います。文字列が数百個、多数のファイルに散っていて、Delete のような短いラベルからリンクやアイコンを含む文章まで粒度がまちまちです。言語スイッチャーを置く自然な場所も UI に用意されていませんでした。
メンテナ(Rainer Simon 氏)と Issue(#305)でやり取りした内容を踏まえ、次のように進めました。
- フレームワークは react-i18next(メンテナも経験があり、lingui も選択肢に挙がっていました)
- メンテナからは「まず別ブランチで小さく進めたい」という意向があったので、最初に足場(scaffold)だけの小さな PR で構造を合意し、本体は自分の判断でページ単位の複数 PR に分割
- スイッチャーは暫定的に start ページ(作業フォルダ選択画面)に配置(メンテナの提案)
「ページ単位に分ける」という粒度は自分で決めたもので、メンテナからの指定ではありません。レビューしやすさを優先した選択です。
namespace はページ領域ごとに切る
ロケールリソースは、言語 × namespace の二次元で切りました。
src/locales/
en/
common.json # 共有コンポーネント
annotate.json # アノテーション画面
images.json # 画像一覧
knowledgegraph.json
...
ja/
common.json
annotate.json
...
namespace をページ領域(=後で分割する PR の単位)に揃えたのがポイントです。こうすると「この PR ではこの namespace だけを足す」という対応が取れ、レビューもしやすくなります。
コンポーネント側は namespace を指定して t() を呼びます。
import { useTranslation } from 'react-i18next';
export const Open = () => {
const { t } = useTranslation('start');
return <h1>{t('open.welcome')}</h1>;
};
ブートストラップでは各 namespace を import して resources に登録します。このファイルが後で競合の火種になります(後述)。
// src/i18n/index.ts
import enStart from '../locales/en/start.json';
import jaStart from '../locales/ja/start.json';
// ... 13 namespace ぶん
i18n.use(LanguageDetector).use(initReactI18next).init({
resources: {
en: { start: enStart, /* ... */ },
ja: { start: jaStart, /* ... */ }
},
fallbackLng: 'en',
interpolation: { escapeValue: false }, // React 側でエスケープ済み
detection: {
order: ['localStorage', 'navigator'],
caches: ['localStorage'],
lookupLocalStorage: 'immarkus.language'
}
});
言語検出は localStorage → ブラウザ言語 → 英語フォールバックの順です。初回訪問は OS やブラウザの言語を尊重し、ユーザーが切り替えたら localStorage に記憶します。
ナビゲーションも含めて翻訳対象にしています。サイドバーや各ページの見出しまで切り替わります。
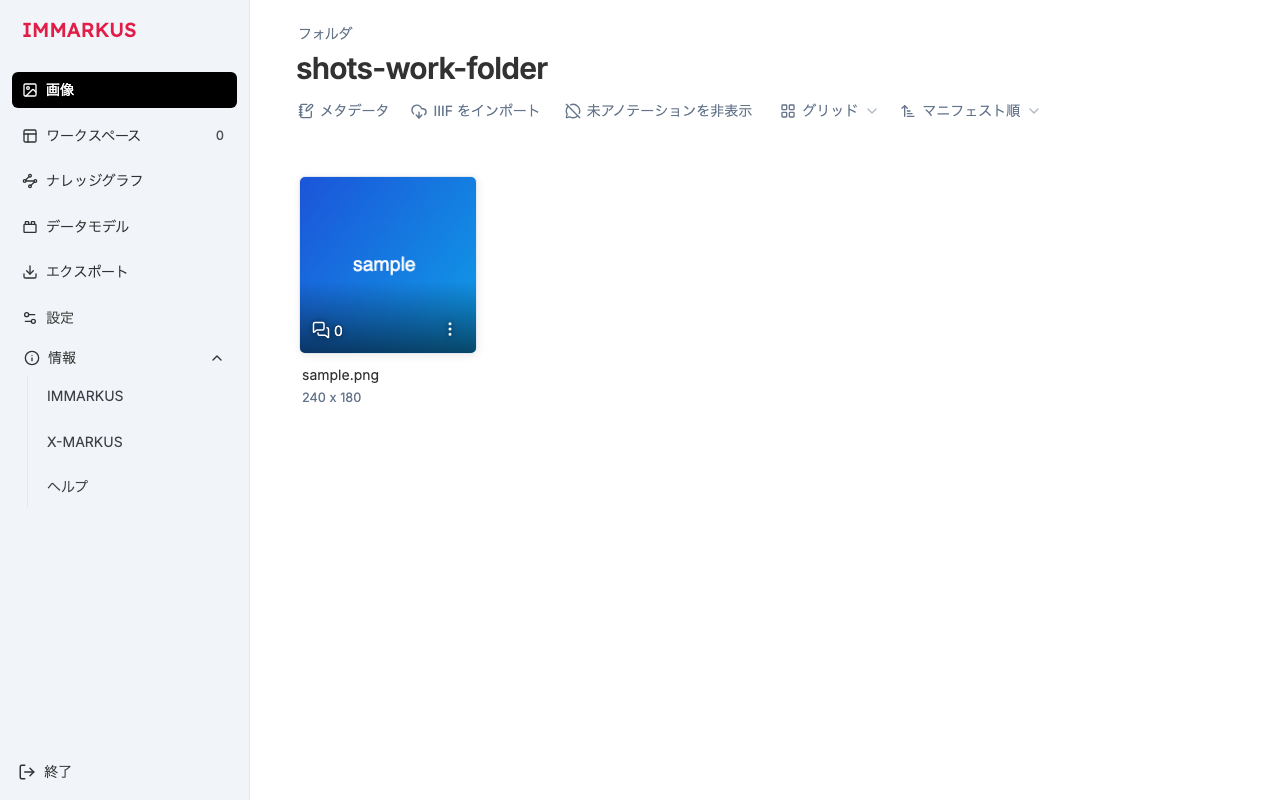 画像一覧。サイドバー(画像・ワークスペース・ナレッジグラフ・データモデル・エクスポート・設定)やヘッダーの操作(メタデータ・IIIF をインポート・未アノテーションを非表示・グリッド・マニフェスト順)も翻訳しています
画像一覧。サイドバー(画像・ワークスペース・ナレッジグラフ・データモデル・エクスポート・設定)やヘッダーの操作(メタデータ・IIIF をインポート・未アノテーションを非表示・グリッド・マニフェスト順)も翻訳しています
文字列をページ単位で抽出する
数百の文字列を 1 か所ずつ順番に潰すと時間がかかり、訳語もぶれます。ページ領域ごとに分担し、共通の前提を揃えてから抽出を進めました。揃えた約束は次のようなものです。
- 確立済みのパターン(
useTranslation/<Trans>/ 階層キー / 複数形)に従う - 用語集を共有して訳語を統一する(annotation=アノテーション、entity class=エンティティクラス、relation=リレーション、knowledge graph=ナレッジグラフ など)
- 翻訳しないものを明示する(
console.*、throw new Error(...)、CSS クラス、固有名詞、ファイル形式名、書誌情報・クレジット)
抽出後の訳抜けやキー不整合は、後述の自動テストで機械的に検出しました。人手のぶれは最終的にそこで拾えます。
翻訳実装で気をつけたこと
複数形は手書きの分岐をやめて i18next に任せる
元のコードには、英語前提の分岐が直書きされている箇所がありました。
// Before(src/pages/datamodel/.../EntityTypeActions.tsx より)
`${children.length} child class${children.length > 1 ? 'es' : ''} will be moved ...`
これは日本語に訳せませんし、英語の複数形ルールもハードコードされています。i18next の複数形機能に置き換えます。
// en(_one / _other)
{
"confirmDeleteWithChildren_one": "This action will delete the entity class from the vocabulary. {{count}} child class will be moved to the root of your data model.",
"confirmDeleteWithChildren_other": "This action will delete the entity class from the vocabulary. {{count}} child classes will be moved to the root of your data model."
}
// ja(日本語は複数形が 1 種類なので _other だけ)
{
"confirmDeleteWithChildren_other": "この操作により、エンティティクラスが語彙から削除されます。{{count}} 件の子クラスはデータモデルのルートに移動されます。"
}
// After
t('entityTypeActions.confirmDeleteWithChildren', { count: children.length })
日本語ロケールが _one を持たないのはバグではなく、これで正しい挙動です。Unicode CLDR の複数形ルール(Intl.PluralRules や i18next が参照するもの)では、日本語の複数カテゴリは other の 1 種類だけだからです。後述のテストでも「日本語は _one を欠いてよい」と明示的に許容しています。
リンクやアイコンを含む文は <Trans>
文の途中にリンクや <b>、アイコンが入る場合、文字列を分割すると翻訳者が文脈を失います。<Trans> を使うと、文章を 1 単位のまま、プレースホルダにコンポーネントを差し込めます。
<Trans
ns="start"
i18nKey="open.hint"
components={{
wikiLink: <a className="text-sky-700 underline" href="https://github.com/rsimon/immarkus/wiki" target="_blank" />
}} />
{
"open": {
"hint": "既存の作業フォルダ、または画像ファイルの入った新しいフォルダを開いてください。IMMARKUS は初めてですか? <wikiLink>詳しくはこちら</wikiLink>"
}
}
説明文や凡例のように、文が長めの画面でもこの方針で通せます。
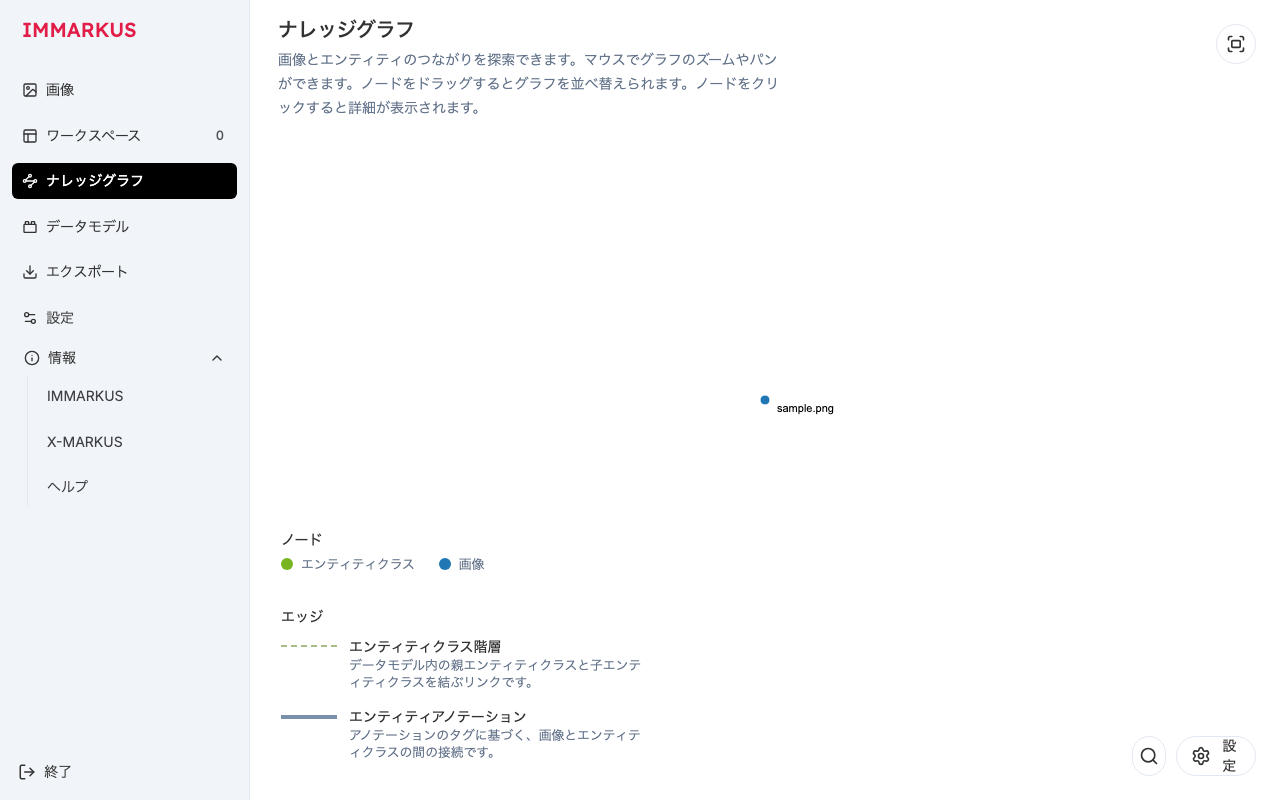 ナレッジグラフ。本文・凡例(ノード/エッジの種類と説明)まで翻訳しています。グラフ上のノードラベル(sample.png)はデータ値なので翻訳対象外です
ナレッジグラフ。本文・凡例(ノード/エッジの種類と説明)まで翻訳しています。グラフ上のノードラベル(sample.png)はデータ値なので翻訳対象外です
日付は date-fns のロケールを UI 言語に追従させる
format(date, 'H:mm MMM dd') のような日付整形は、そのままだと月名が英語で残ります。UI 言語に応じて date-fns のロケールを渡す薄いヘルパーを用意しました(実際のコードは型注釈付きですが、要点は次の通りです)。
// src/i18n/dateLocale.ts
import { ja } from 'date-fns/locale';
import i18n from './index';
const DATE_LOCALES = { ja };
export const getDateLocale = () => DATE_LOCALES[i18n.language?.split('-')[0]];
format(lastEdit, 'H:mm MMM dd', { locale: getDateLocale() });
formatDistanceToNow(date, { addSuffix: true, locale: getDateLocale() });
テストが無いリポジトリにテストを足す
このリポジトリには、調べた限りテストが 1 つもありませんでした(package.json の scripts は start / build / preview のみ)。i18n は訳キーの抜けが実行時に黙って英語フォールバックする領域で、目視では気づきにくいので、テストを入れておくと効きます。
vitest:ロケールのキー整合を機械チェック
導入したのは 2 系統です。
- en と ja のキー整合:全 namespace で、片方にあるキーはもう片方にもある(日本語は
_one複数形だけ欠いてよい) - コード参照の解決:ソース中の
t('...')や<Trans i18nKey="...">のリテラルキーが、英語リソースに実在する
2 番が地味に効きます。キーをリネームしたり削除したのに呼び出し側を直し忘れた、というデグレを CI(継続的インテグレーション)で止められます。
導入時には、テスト自体が本当に検出するかを確かめるために、わざとキーを 1 つリネームして全テストが落ちること、戻すと通ることも確認しました。
Playwright:showDirectoryPicker を OPFS でモックする
エンドツーエンド(e2e)テストの最大の障壁は、IMMARKUS が File System Access API(window.showDirectoryPicker)で作業フォルダを開かないと中の画面に入れない点でした。ネイティブのフォルダ選択ダイアログは自動化できません。
そこで showDirectoryPicker を OPFS(Origin Private File System、navigator.storage.getDirectory())ベースのディレクトリで差し替え、サンプル画像も書き込むヘルパーを用意しました。
// e2e/helpers.ts(抜粋)
export const mockWorkFolder = (page: Page) =>
page.addInitScript(async () => {
(window as any).showDirectoryPicker = async () => {
const root = await navigator.storage.getDirectory();
const dir = await root.getDirectoryHandle('e2e-work-folder', { create: true });
// ここで sample.png を 1 枚書き込む(冪等)
// ...
(dir as any).requestPermission = async () => 'granted';
return dir;
};
});
これで、フォルダを開いた先の画面も Playwright で検証できるようになりました。各テストでは、期待する訳文が描画されることに加えて、画面に生キー(open.welcome のような未解決のキー文字列)が漏れていないこと、ページエラーが出ていないことも確認しています。
下はアノテーション画面で、e2e の主な検証対象の 1 つです。アノテーション編集中の重い画面も、OPFS モックを通せば自動で開けます。
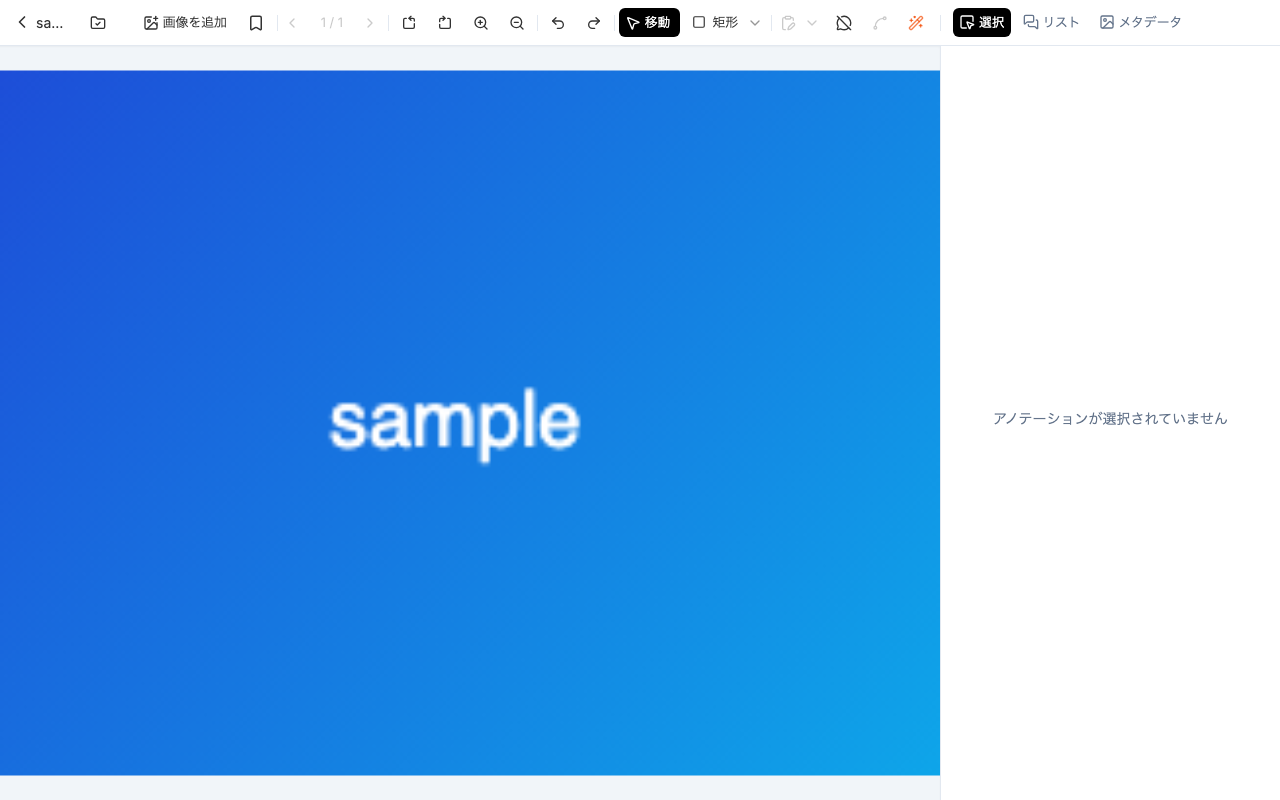 アノテーション画面。ツールバー(画像を追加・移動・矩形 など)や右サイドバー(選択・リスト・メタデータ)も翻訳済みです
アノテーション画面。ツールバー(画像を追加・移動・矩形 など)や右サイドバー(選択・リスト・メタデータ)も翻訳済みです
なお、生キー検出はドット区切りの語を拾う素朴な仕組みなので、About ページの doi.org/... のような実 URL を誤検知します。これらは <a> 内のテキストを除外してからアサートしました(このような正規の例外は握りつぶさず、明示的に扱うようにしています)。
PR をページ単位に分けて出す
足場 PR をマージしてもらったあと、本体をページ単位の PR として順に出しました。1 つの PR には、対象ページの翻訳・該当 namespace の JSON・その namespace の登録・ページごとの e2e を含めています。
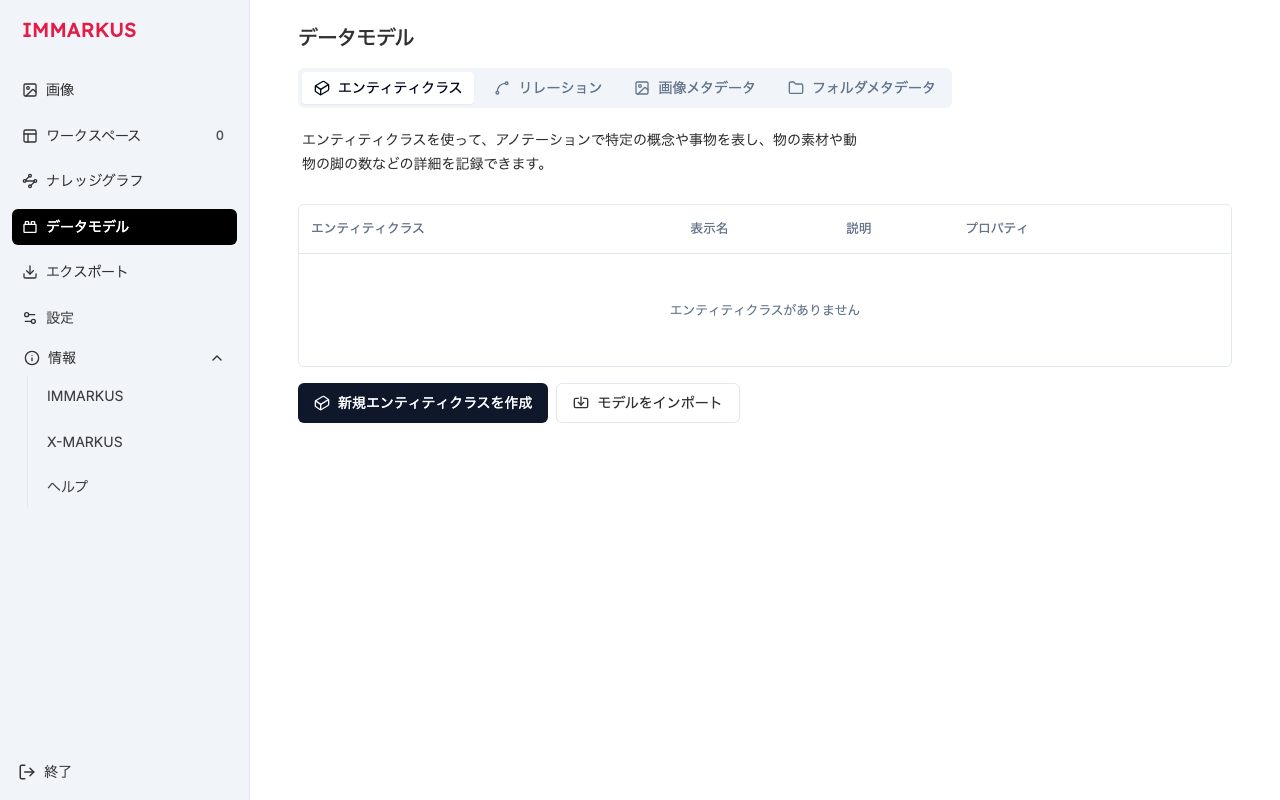 データモデルページ。タブやテーブルのヘッダー、空状態のメッセージまで翻訳しています
データモデルページ。タブやテーブルのヘッダー、空状態のメッセージまで翻訳しています
メンテナのマージが速かったため、ある PR をマージしてもらっている間に別の PR を準備する、という流れで進みました。実際、ページ系の 5 本は 30 分ほどの間に続けてマージされています。このテンポ自体はありがたいのですが、後述の競合とは相性が悪い面もありました。
後から並行で PR を出すときに踏んだこと
ここからは、成熟した OSS に並行して PR を出すときに特有の、いくつかの注意点です。
1. e2e が通っても upstream を壊していないとは限らない
ページ単位で PR を出している途中、メンテナが Export と Settings まわりを並行して改修していました。具体的には、Export のナビが共有コンポーネント NavTabItem に置き換わり、Settings の General 設定が独立したコンポーネント(general/General.tsx)として切り出されていました。
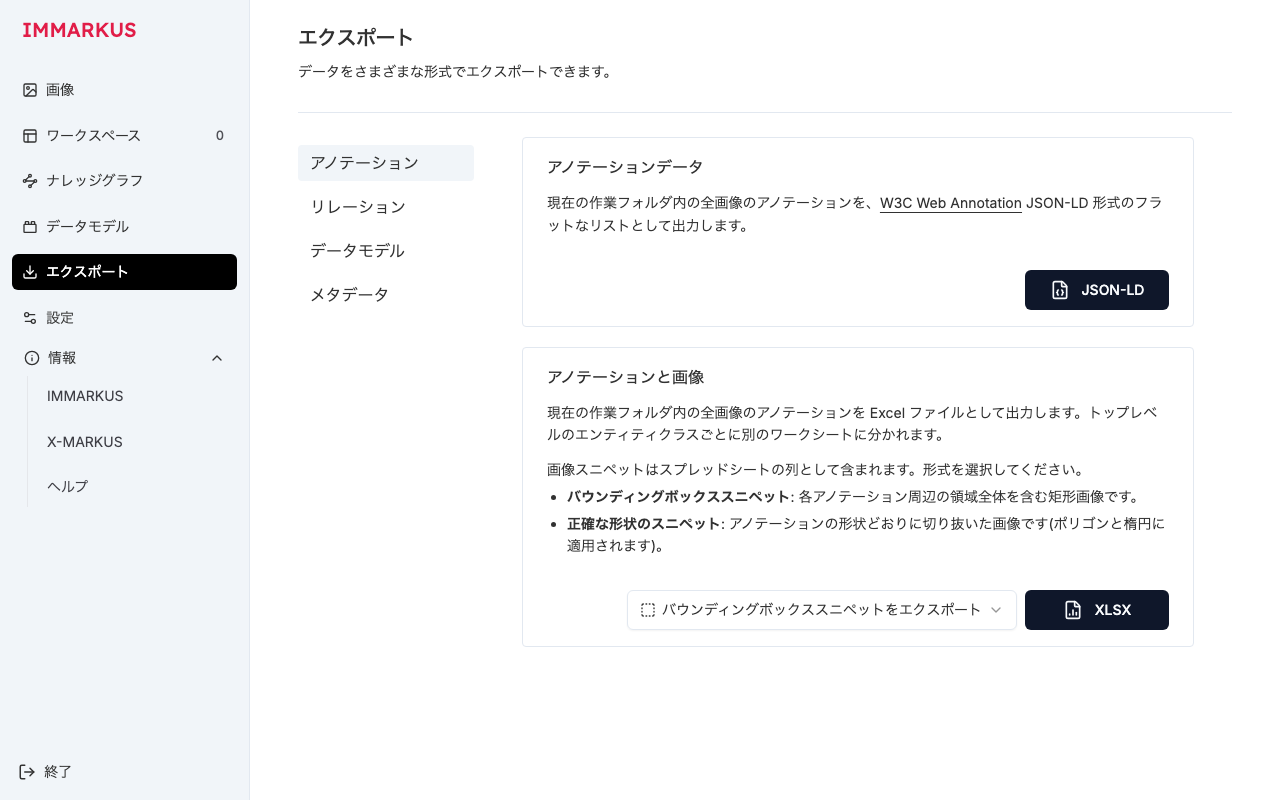 エクスポートページ。ナビは作業中に upstream で
エクスポートページ。ナビは作業中に upstream で NavTabItem へ移行していたため、自分の古い翻訳を当てると改修を巻き戻すおそれがありました
ここで注意が要るのは、自分の手元にある古い翻訳済みファイルをそのまま当てると、メンテナの改修を巻き戻してしまう点です。やっかいなのは、巻き戻した版に対して e2e を流しても、たいてい普通にパスしてしまうことです。テストは「自分が戻した古い構造」を検証するので、緑になっても upstream を壊しているかどうかは分かりません。
対策として、git で構造的な差分を取りました。自分の作業のベースと現在の upstream を、ページのディレクトリに絞って比べます。
# 翻訳前ベース(作業開始点)と現在の upstream/main を比較
git diff --stat <base> upstream/main -- src/pages/export
差分が空でなければ「upstream 側で改修が入った=自分の翻訳は陳腐化しているかもしれない」と判断できます。ただしこの差分は空白や無関係な import のような些細な変更でも反応するので、厳密なクロバー検出というより「作り直しを検討する合図」くらいに捉えるのがよさそうです。今回は Export と Settings の陳腐化をこれで把握し、現行コードに対して翻訳をやり直しました。
2. 共有ファイルを全 PR が触ると、マージのたびに競合する
namespace を登録する src/i18n/index.ts を、並行して開いた全 PR が編集します。各 PR は自分の import 行と resources のエントリを足すだけですが、全部が同じブロックに同じベースから追記するため、1 本がマージされた瞬間に残りがこのファイルで競合します。
幸い競合は index.ts(と一部の共有ヘルパー)だけなので、解決は「main にある namespace と、その PR の namespace の和集合を書く」だけの機械的な作業です。毎回ローカルでビルドとテストを通してから force push し、メンテナ側に競合を見せないようにしました。とはいえ、マージのたびにこれが連鎖するので、本数が多いと地味に手間です。
連鎖を根本から避けるなら、登録を手書きせず、Vite の import.meta.glob で src/locales/<lang>/*.json をまとめて読み込む方法があります。{ eager: true } を付ければビルド時に静的にバンドルされるので、ページ PR は JSON を置くだけで index.ts を触らずに済み、競合しなくなります。今回はメンテナが明示的な import を手で書いていた経緯もあって手動追従にしましたが、最初からスケールを見込むなら自動読み込みにしておく手はあったと思います。
3. メンテナと作業がぶつからないようにする
「言語スイッチャーを Settings ページにも置きたい」という話があり、これはメンテナ自身が実装してくれました(Settings の General タブにスイッチャーを配置)。そのため、自分の settings 関連の PR ではスイッチャー本体には触れず、周囲のラベルだけを翻訳しています。
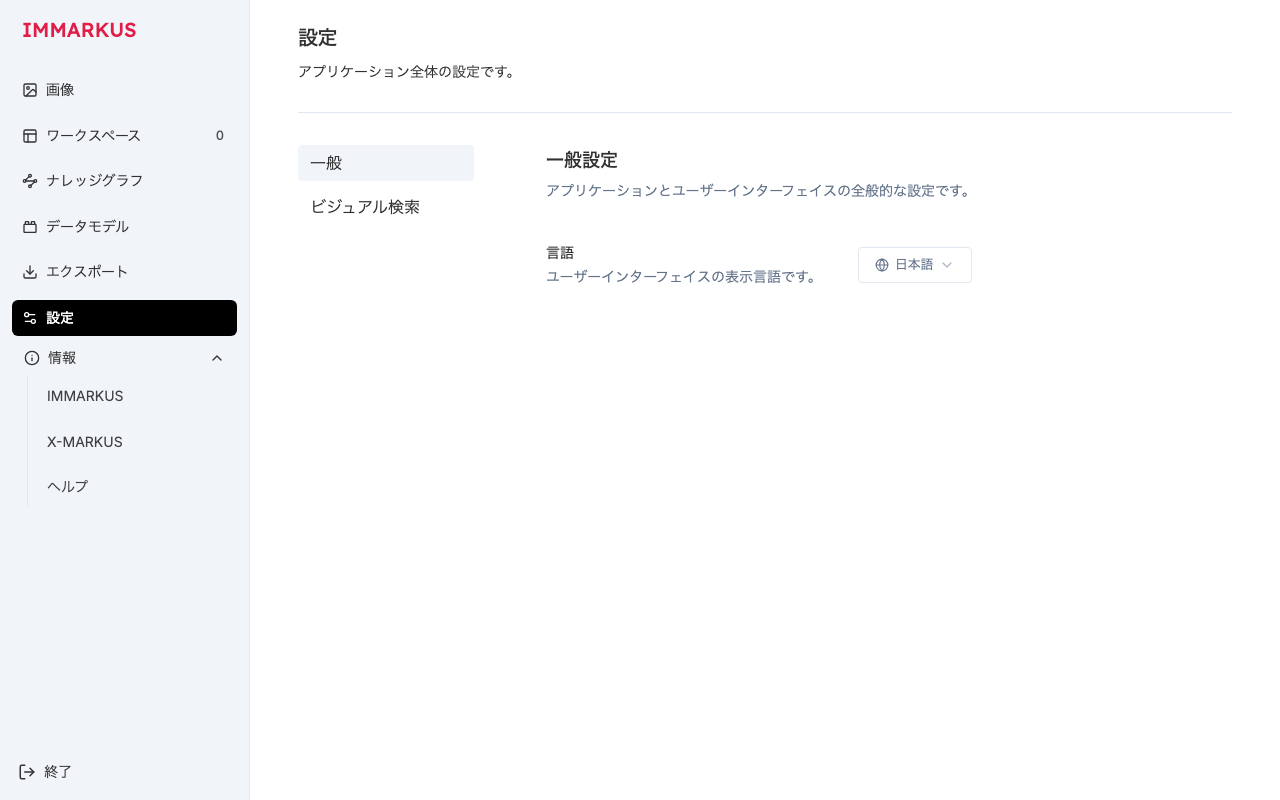 設定ページの General タブ。スイッチャー本体はメンテナの実装で、
設定ページの General タブ。スイッチャー本体はメンテナの実装で、言語・説明文・一般設定 などの周囲のラベルだけを翻訳しています
OSS では相手も同じファイルを動かしている前提で、触る範囲を最小限に切るのが衝突回避の基本になります。各 PR では対象ページのファイルだけを取り込み、メンテナが変更した Start.tsx や LanguageSwitcher を古い版で上書きしないように注意しました。
残した部分と、次に手を入れるなら
今回は翻訳していない部分もあります。
src/servicesの ServiceRegistry 由来の文字列(外部サービス名や API キーの取得手順など)は、設定データ層での i18n 設計が別途必要なため未対応にしています- About / X-MARKUS の書誌情報・クレジット・ERC の助成金表記は、固有名詞や引用なので原文のままにし、周囲の説明文だけを翻訳しています
言語の追加自体は、src/locales/<lang>/*.json を足してスイッチャーの候補に加えるだけで済みます(複数形ルールは i18next 側が言語ごとに判断します)。
振り返って効いたこと
後付けの i18n でやってよかったと感じた点を、最後に整理します。
- namespace を「分割する PR の単位」に揃えると、抽出・レビュー・段階的な導入が噛み合いやすい
- 複数形・リンク入りの文・日付は、手書きのロジックをやめて i18next・
<Trans>・date-fns のロケールに寄せる - 訳抜けは目視で気づきにくいので、キー整合と参照解決の自動テストを早めに入れる
- File System Access API のような自動化が難しい API は、OPFS でモックすると e2e に乗せられる
- 並行 PR では、e2e の緑だけに頼らず git の差分で upstream の改修を確認し、共有ファイルの競合を見越して登録を自動化するか、こまめに rebase する
テストが無く、ある程度成熟していて、メンテナが活発に動いている OSS に、横断的な変更を後から入れる、という状況に共通して効く話だと思います。


コメント
…