本記事は生成AI(Claude Code)と共同で執筆・制作しています。事実関係は可能な範囲で確認していますが、誤りが含まれている可能性があります。重要な判断の前にはご自身でも一次情報をご確認ください。
デジタル・ヒューマニティーズの技術要素(TEI、RDF、…)を1要素=1本で解説する、個人企画の動画シリーズを作っています。スライド1枚ずつにナレーションを当て、自分の声のクローンで読み上げる15〜20分の技術解説動画です。本記事は、その制作で得た実務的なノウハウ — Marp の手描き風スライド、声クローン録音用の自作ツール、そして ElevenLabs の Professional Voice Clone(PVC)× v3 を実運用したときの落とし穴 — を、RDF 入門の回を例にまとめます。
声クローンそのものの品質比較や、ブログ記事からの動画自動生成については既存記事で扱っています。本記事はそれらを前提に、「スライド形式の技術解説動画」を仕上げるための工程に焦点を当てます。
- ElevenLabs v2 と v3 の日本語朗読品質比較
- VOICEVOX 動画パイプラインの読み補正アプローチを比較する
- Claude Code の並列エージェントで882本のブログ記事から解説動画を自動生成した話
作ったもの
技術要素シリーズの1本「RDF とリンクトデータ入門」。共通の体裁(大タイトル+サブタイトル、手描き風テーマ)で、1920×1080・15〜20分。

スライドは Marp で作って PNG に書き出し。ナレーション原稿は sections.json(スライド番号 → ナレーション文のリスト)として持ち、ElevenLabs で合成、ffmpeg で「無音のスライド映像 + 全体音声」を後から一括 mux して同期させます。
Marp(.md) ──→ page-NN.png(1920×1080)
sections.json(slide:N, narration:"…")
│
▼ ElevenLabs PVC × v3(with-timestamps)
チャンク音声 + 文字単位タイムスタンプ
│ タイムスタンプで「次スライド最初の文字の発話開始」を境界に分割
▼
無音スライド映像を連結 + 全体音声を一括 mux ──→ video_main.mp4
スライドの「手描き風の図」はどう作っているか
スライドの図(ぽんち絵)は、温かみのある手描き風にしています。ポイントは Marp は静的で JavaScript を実行しないこと。そのため、図は roughjs で事前に SVG へ焼いてからスライドに埋め込みます。
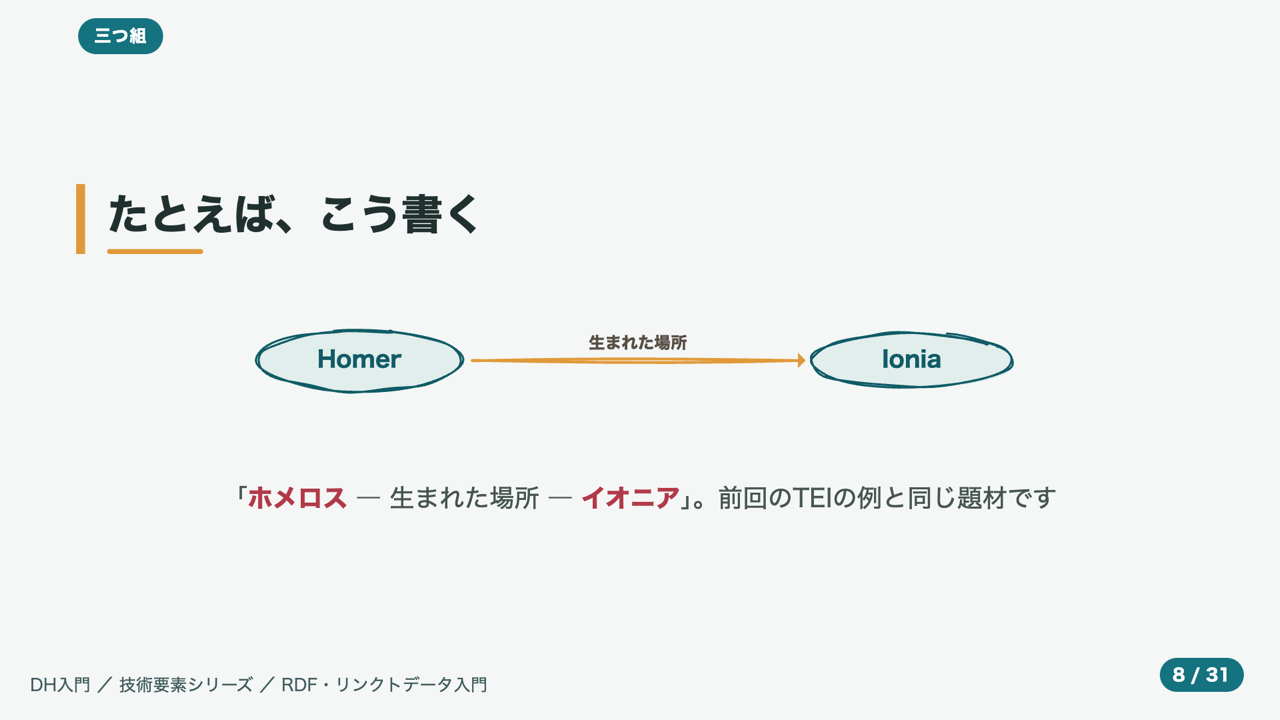
gen.mjs というスクリプトで、roughjs の generator を使って図形(矩形・楕円・線・矢印)を生成し、gen.toPaths() で SVG の <path> に変換、figures/*.svg に保存します。node gen.mjs で一括生成し、スライドからは <img src="figures/triple.svg"> で読み込むだけ。手描きの「ゆらぎ」は roughness と bowing というパラメータで出ます。
import rough from 'roughjs';
const gen = rough.generator();
// roughjs の図形 → SVG パス文字列に変換
const toP = (d) => gen.toPaths(d).map(p =>
`<path d="${p.d}" fill="${p.fill||'none'}" stroke="${p.stroke||'none'}"
stroke-width="${p.strokeWidth||0}" stroke-linecap="round"/>`).join('');
// 手描き感の核:roughness(線の荒さ)と bowing(たわみ)
const o = (x={}) => ({ roughness: 1.7, bowing: 1.4, stroke: '#0f5b66', strokeWidth: 2.4, ...x });
const ellipse = (cx, cy, w, h, x2) => toP(gen.ellipse(cx, cy, w, h, o(x2)));
// ノード(楕円+中央ラベル)などを部品化しておく
const node = (cx, cy, w, label) =>
ellipse(cx, cy, w, 66, { fill:'#e2eeec', fillStyle:'solid' }) +
`<text x="${cx}" y="${cy+8}" text-anchor="middle" ...>${label}</text>`;
// 「主語 —述語→ 目的語」の三つ組を1枚に
let b = node(140,100,220,'主語') + node(460,100,220,'述語') + node(780,100,220,'目的語');
b += arrowH(255,345,100) + arrowH(575,665,100);
writeFileSync('figures/triple.svg', `<svg ...>${b}</svg>`);
設計上のルールも決めています(制作ガイドライン §4)。
- 1図=1関係(フロー/対比/入れ子/グラフのどれか一つ)。
- 色だけに依存しない(色覚多様性のため、明度差+形+直接ラベルで区別)。
- 横に語を並べる行は
<tspan>で1行に流すヘルパ(richLine)を使い、座標を手置きして隣の語と衝突するのを防ぐ。 - 図には必ず 代替テキスト(alt) を付け、さらに図の要点はナレーションでも言語化する(音声だけでも分かるように)。
- 原典の図はトレースしない。概念だけ参照して新規に描く(ライセンス配慮)。
roughjs は「実行時にcanvasへ描く」使い方が一般的ですが、ここでは
generatorでパス文字列だけ取り出して 静的SVGに焼く のがミソです。Marp/PDF/動画のどれでも同じ図が再現でき、ビルドも速くなります。
ツール①:クローン学習用の「録音テレプロンプター」
PVC は自分の声のサンプルを学習させて作ります。きれいなサンプルを安定して録るために、読み上げ速度に合わせて文字が赤く塗られていくテレプロンプターを自作しました(下図はサンプル文を読み込ませた状態)。
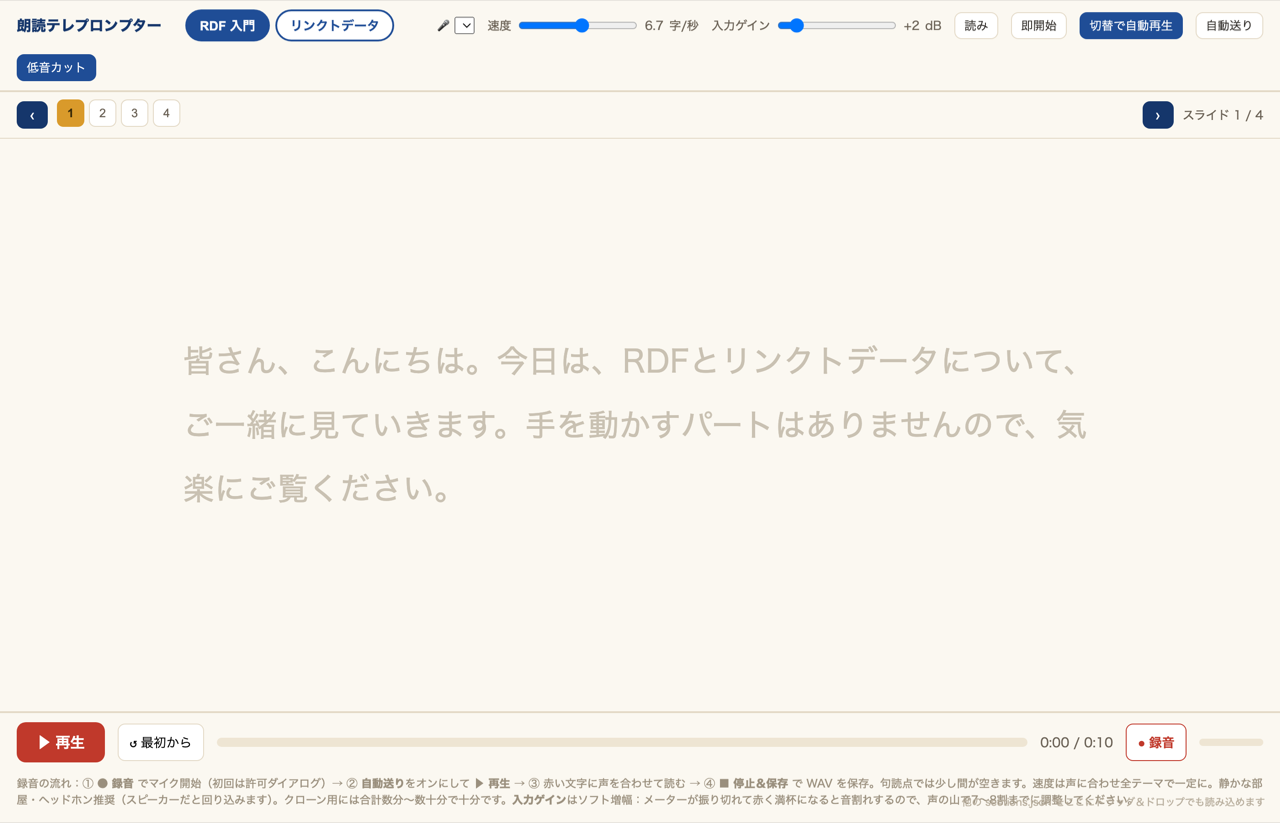
- カラオケ式の赤字進行:目標速度(字/秒)で文字が塗られるので一定のテンポで読める。句読点では少し間を取るよう重み付け。
- スライド切替で自動再生:カウントダウンを挟まず、送ると即読み始められる(録り直しのテンポが上がる)。
- 生(無加工)の WAV をブラウザで保存:クローン学習にはノイズ抑制やオートゲインがかかっていない素の音声が望ましいので、
echoCancellation / noiseSuppression / autoGainControlをすべてfalseにして録る。 - 入力ゲイン・低音カット・マイク選択:USB コンデンサマイク前提で、空調などの低周波を切る HPF とレベル調整用の入力ゲインを用意。
アプリ側のノイズ抑制は「相手に届く声」を整える用途。学習用には素の音声、と使い分けるのがポイントです。録音レベルやノイズフロアは
ffmpegのastatsでピークレベル/RMS/ノイズフロアの数値を見て調整しました(波形そのものを見たいときはshowwaves等を使います)。
PVC × v3 の勘どころ
v2 か v3 か、PVC か IVC か
日本語の自然さでは v3 が明確に上(v2 は英語訛りが残りがち)。一方で v3 には実運用上のクセがあります。
speedでの調整が効かない(当方の実機観察)。speed(0.7〜1.2)は公式には全モデルで使えるとされますが、PVC×v3 を実運用した範囲(2026-06時点)では期待した速度変化が得られませんでした。テンポはパラメータに頼らず原稿側で整えます(後述)。- 長い単一生成で末尾が崩れる/繰り返す(実機での経験則)。当方では概ね 2,000〜3,000字あたりから不安定でした。公式の1リクエスト上限は約5,000字なので、安全側に小さめのチャンクに分けます。
- PVC(Professional Voice Clone)は複数モデルへファインチューンでき、学習済み PVC を v3 の with-timestamps 合成に使うことも実機で可能でした(2026-06。タイムスタンプも返る)。これでスライド同期と自然な日本語を両立できます。ただし公式は「PVC は現状 v3 に最適化しきれておらず、クローン品質が落ちうる」と注意しているので、品質重視なら v3 向けは IVC や designed voice も検討材料になります。
補足(当方の実機観察):PVC の再学習(re-fine-tune)中は、API が一時的に
voice_not_fine_tunedを返して使えなくなりました。完了すれば v3 でも再び 200 で通るようになりました。
テンポは「読点の間引き」で整える
speed での調整が効かないので、v3 のテンポは原稿の読点(、)の量で調整します。実際、ある原稿だけ妙に遅く・たどたどしく聞こえたので調べたら、その原稿だけ読点が突出して多い(当方の実測で1文あたり4.7個、他は1.6〜2.4個)状態でした。v3 は読点ごとに小さなポーズを入れるため、読点が2〜3倍あると同じ字数でも大幅に遅くなります。過剰な読点を間引くだけでテンポが揃い、尺も縮みました。
「音色の継ぎ目」を余韻でマスクする
v3 は request stitching も previous/next text も非対応なので、原稿を複数チャンクに分けて合成すると、各チャンクは完全に独立した別生成になります。結果、チャンクの境界でトーンやテンポがわずかに変わる「音色の継ぎ目」が出ます(1,300字チャンクなら5,000字で約4チャンク=継ぎ目は3箇所ほど)。スライド送りがこの継ぎ目と重なると、視覚カット+音色変化が同時に来て一層気になります。
継ぎ目自体は消せませんが、チャンク境界は必ずスライド境界に一致する性質を使って、そこに短い無音(余韻)を挿入してマスクしました。合成スクリプトに --chunk-gap を追加し、継ぎ目に0.9秒の無音を入れています。映像側も各チャンク末尾スライドに同じ秒数を足すので、A/V 同期は保たれます。
python3 build_slideshow_narration.py <lecture_dir>/ \
--single-call --max-chunk-chars 1300 \
--stability 0.6 --chunk-gap 0.9 \
--voice-id <PVC_VOICE_ID> --model eleven_v3
秒数の目安は、普通のスライド切り替え(チャンク内)にある自然なポーズ ≒ 0.5〜0.8秒(v3 が文末「。」に作る間。当方の原稿・声・設定での実測)との対比で決めました。継ぎ目はスライドの塊の切れ目なので、自然なポーズより少し長い 0.9秒が「セクションの区切りの呼吸」として自然に聞こえます(1.2秒を超えると間延びします)。あわせて --stability を 0.6〜0.7 に上げると、チャンク間のトーン変動そのものも小さくなります(抑揚はわずかに減)。
余韻だけの微調整なら --skip-audio を付けることで再合成せず(クレジットを使わず)動画だけ作り直せます。
ツール②:継ぎ目をピンポイントで確認する「seam_review」
継ぎ目の余韻を 0.6 → 0.9 秒のように詰めて評価するには、毎回その箇所を頭出しして聞く必要があります。そこで、境界をワンクリックで頭出し再生する HTML を生成するツールを作りました。_slide_specs.json(合成時に保存される各スライドの尺)から境界時刻を再計算し、動画を埋め込んだレビューページを出力します。
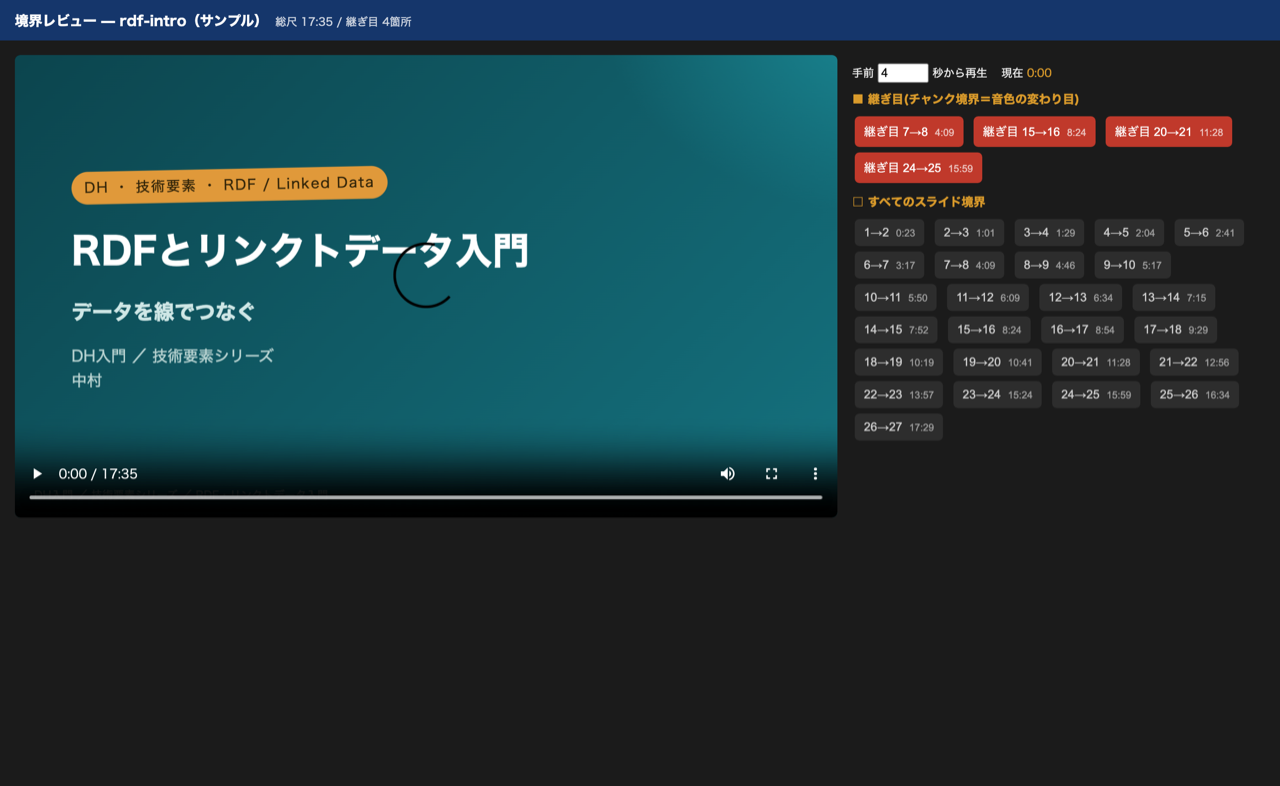
- 赤いボタン=継ぎ目(音色の変わり目)。クリックで数秒手前から自動再生。
- 下のグレーのボタン=全スライド境界。任意の切り替わりも確認できる。
python3 seam_review.py <lecture_dir>/ --chunk-gap 0.9
読み間違いの検出と補正
合成音声は固有名詞や難読語を読み違えます。本パイプラインには読み辞書(reading_overrides.csv=Excel の読み修正リスト)と適用スクリプト(apply_readings.py)があり、sections.src.json(漢字の正本)に辞書を適用して sections.json(合成入力)を生成します。今回得た教訓:
- 「漢字+かな」の読み併記は禁物。原稿に「悉皆、しっかい、」のように書くと、v3 は漢字を読み(しかも誤読し)、さらにかなも読む=二重読みになる。かなだけにする。
- VOICEVOX で正しく読めても v3 が誤読することがある。実際「悉皆」は VOICEVOX では「シッカイ」と正読したのに、v3 は「しこぎな」と読みました。つまり自動チェック(VOICEVOX のカナ展開)では v3 の誤読を予測しきれない。難読語は機械チェックで候補を絞り、最終的には耳で確認するのが確実です。
- 自己紹介の名前など、発音が不安定で気になる固有名詞は、読みやすい表記にしてしまうのも手。
読み補正アプローチの比較はこちらの記事に詳しくまとめています。
シリーズ全体の重複を「回帰テスト」のように校正する
複数本のシリーズ(TEI 入門、RDF 入門…)は、放っておくと**通しで見たときに「また同じ話だ」**となりがちです。そこで、
- 各概念に「主担当の回」を一つ決め、他の回は軽く触れるに留める(MECE)。
- 原稿を複数のエージェントで観点別(概念/具体例/通し聴き)に重複監査し、指摘を反映。
- 反映後に同じ監査を再実行(プログラミングのテストのような回帰チェック)。合格まで「修正→再監査」を繰り返す。
という運用にしました。ここで重要だったのは、「各動画は独立して完結させたい(相互参照を増やしたくない)」という方針と、「重複ゼロ」は同時には達成できないという気づきです。監査は何度回しても「前回は〜、今回は〜と接続句を入れれば連続性に転じる」と勧めてきますが、それは独立性の方針と衝突します。概念の重複はある程度は主題の共有に由来する不可避なものと割り切り、内部の明白な冗長(同じ言い回しの3連続など)を潰した段階で監査ループを止める、という判断が要りました。
並列エージェントによるレビューの考え方はこの記事の延長線上にあります。
ガイドラインを SSOT にする
これらの判断は、その場限りにせず制作ガイドライン(Single Source of Truth)に都度追記しました。「継ぎ目に0.9秒の余韻」「読み併記は二重読みになるので避ける」「v3 のテンポは読点で調整」といった、一度ハマらないと分からない知見ほど、文書化しておくと次の回で効きます。
まとめ
- スライド形式の技術解説動画は Marp → sections.json → ElevenLabs PVC×v3 → ffmpeg 一括 mux で組める。
- 図は roughjs で静的SVGに焼いて埋め込む(Marp は JS を実行しないため)。
roughness/bowingで手描き感。 - v3 は自然だがクセがある:
speedが効かない/長生成で崩れる/チャンクが独立生成で継ぎ目が出る。 - テンポは読点の量で、継ぎ目は境界に0.9秒の余韻でマスクする。
--skip-audioなら無課金で詰められる。 - 読み間違いは機械チェックで候補を絞りつつ最終は耳。「漢字+かな」併記は二重読みになる。
- シリーズは MECE + マルチエージェント回帰レビューで校正。ただし独立性と重複ゼロは両立しないので止めどころを決める。
- 得た知見は ガイドライン(SSOT)に追記して次に活かす。

コメント
…