本記事は生成AIと共同で執筆しています。事実関係は可能な範囲で公式ドキュメント等と照合していますが、誤りが含まれている可能性があります。重要な判断を行う前にご自身でも一次情報をご確認ください。
本記事では、特定の運営者を指し示さないよう、対象サイトのドメイン・パス・識別子は伏せ字(
museum.exampleなどのプレースホルダ)にしています。技術的な構成の記録が目的で、特定サイトからの収集手順を示すものではありません。
調べたことと結論
ある公開コレクション(美術館)について、画像とメタデータを API 経由で取得できるかを調べました。調査した範囲での結論は次の通りです。
- メタデータは公式の JSON API で取得できる(キー不要で、利用も公認されている)
- 画像URLは、その API のレスポンスには含まれていない
- 画像は別ドメインの CDN(DAM 製品の配信)にあり、URLは作品詳細ページの HTML 内にのみ現れる
- 詳細ページは Cloudflare Bot Fight Mode の対象で、素の
curlやヘッドレスブラウザでは 403 が返る - robots.txt は詳細ページの自動収集を対象外(Disallow)としている
「公開されているか」と「機械可読に取得できるか」と「取得してよいか」が、それぞれ別の問いとして分かれていた点が興味深かったので、調査の過程を記録として残します。なお robots.txt の方針を尊重し、全件の収集・データセット化は行っていません。
メタデータは公式 API で取得できる
運営者は公式のコレクションAPIを公開しています。ドキュメントによれば、キー不要・レート制限なし(現時点)とされています。
https://museum.example/api/v1/collection?search_api_fulltext=<検索語>
search_api_fulltextに検索語を渡して絞り込みます(検索語を与えない場合は既定の一覧が返りました)- 1ページ10件で、
page=でページ送りします
返ってくる JSON の1レコードは次のような構造です(28フィールド。値はプレースホルダに置換)。
{
"id": "<object-id>",
"title": "<作品タイトル>",
"primaryMaker": "<作者名>",
"makers": [{ "name": "<作者名>", "years": "<生没年・出身>", "nationality": ["<国籍>"] }],
"medium": ["<技法・素材>"],
"datingYearFrom": "<制作年>", "datingYearTo": "<制作年>",
"dimensions": "<寸法>",
"objectNumber": "<整理番号>",
"publicDomain": null,
"type": ["<分類>"],
"url": "https://museum.example/collection/<slug>"
}
メタデータとしては十分にリッチですが、画像URLのフィールドは含まれていません。あるのは作品ページへの url と publicDomain フラグです。
画像の所在
url の作品詳細ページを開いて <img> を確認すると、画像はすべて別ドメインから配信されていました。
https://<alias>.cdn.picturepark.com/v/<8文字トークン>/
DAM(Digital Asset Management)製品である Picturepark Content Platform(現在は Fotoware 傘下で "Fotoware Alto" へ改名が進んでいるようです)の配信URLです。<alias> は契約者ごとのサブドメインです。調査した限り、このトークンは API のレスポンスには含まれず、詳細ページの HTML にのみ埋め込まれていました。
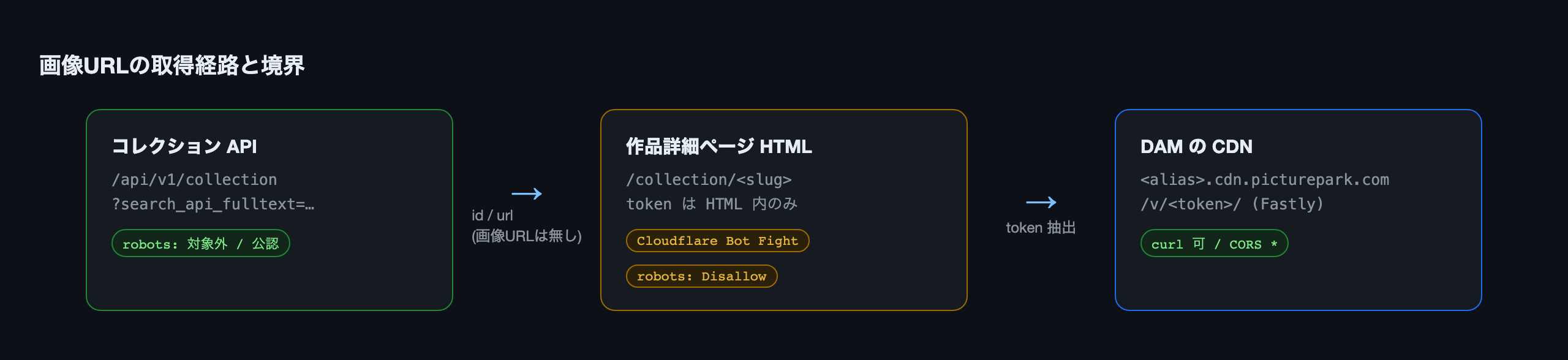
したがって画像URLを得る経路は次のようになります。
API で id と url を取得
→ url の詳細ページHTMLを取得
→ HTML から <alias>.cdn.picturepark.com/v/<token>/ を抽出
Cloudflare Bot Fight Mode の挙動
その詳細ページの取得には一手間ありました。
$ curl -s -o /dev/null -w "%{http_code}\n" https://museum.example/
403
User-Agent を Chrome に合わせても、Accept や Referer を加えても 403 でした。ドメイン全体で素の curl に対して 403 を返します(Cloudflare の "Sorry, you have been blocked" 応答)。
ヘッダではなく TLS/ブラウザのフィンガープリントで判定しているようで、ヘッドレス Chrome(Playwright headless: true)でも 403 でした。特徴的だったのは、cf_clearance クッキーが発行されない点です。クッキー型のチャレンジ通過ではなく、リクエストごとにフィンガープリントを評価しているとみられ、「一度通過して得たクッキーを curl で使い回す」方法は今回は成立しませんでした。
200 が返ったのはヘッド付き(実ウィンドウ)の Chrome でした。
import { chromium } from 'playwright';
const ctx = await chromium.launchPersistentContext('/tmp/profile', {
channel: 'chrome', // 実Chrome
headless: false, // headless: true では今回は弾かれた
});
const page = ctx.pages()[0] ?? await ctx.newPage();
await page.goto('https://museum.example/collection', { waitUntil: 'domcontentloaded' });
await page.waitForTimeout(2500); // 初回チャレンジ通過待ち
一度オリジンを開いた後は、そのページ内から fetch() すると Chrome のネットワークスタックを経由するため Cloudflare を通過しました。これを使うとフルページ描画なしに HTML を取得できます。
const tokens = await page.evaluate(async (url) => {
const html = await (await fetch(url, { headers: { Accept: 'text/html' } })).text();
return [...new Set([...html.matchAll(/picturepark\.com\/v\/([A-Za-z0-9]+)/g)].map(m => m[1]))];
}, detailUrl);
DAM トークンの観察
ここからは /v/<token>/ を実測して分かったことです(トークン値・ファイル名は伏せ字)。
署名も期限もない固定トークン
$ curl -sI https://<alias>.cdn.picturepark.com/v/<token>/
HTTP/2 200
content-type: image/jpeg
content-disposition: inline; filename=OBJ-00000.tif.jpg
etag: "<sha1>"
cache-control: no-cache
access-control-allow-origin: *
via: 1.1 varnish, 1.1 varnish
x-served-by: cache-fra-xxxxxxxx-FRA, cache-nrt-xxxxxxxx-NRT
x-cache: HIT, HIT
age: 591
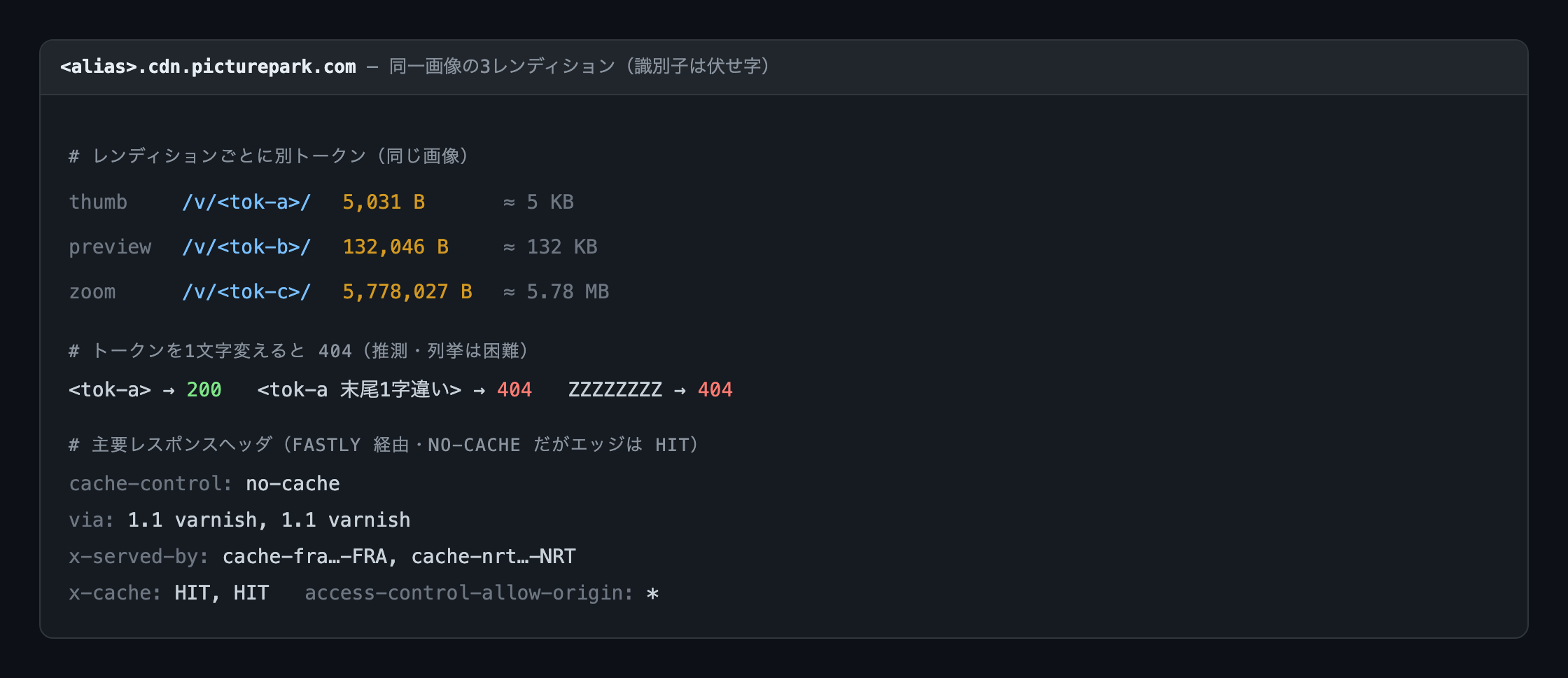
- 署名クエリや有効期限を持たない、パスだけのURLでした。レンダリングごとに発行される一時署名URLではなく、(資産 × レンディション)に対して固定で割り当てられたトークンのように見えます。
- トークンを1文字でも変えると 404 になりました。英数字8文字(base62)の空間は約 2×10^14 で、現時点では推測・列挙は困難なようです。
<token> -> 200
<token末尾1字違い> -> 404
ZZZZZZZZ -> 404
cache-control: no-cacheが返る一方で、Fastly エッジでは HIT していました(ageが増えていきます)。ブラウザには毎回再検証させつつ、エッジはキャッシュを返す構成のようです。via: 1.1 varnishは Varnish ベースのキャッシュを示すもので Fastly 専用ではありませんが、x-served-by: cache-*とx-cacheが併存していることから Fastly とみられます。x-served-byはフランクフルト(FRA)と東京(NRT)の二段になっていました。- マスターは
.tif、配信は.tif.jpgの派生で、ファイル名に整理番号が含まれていました。
レンディションはサイズごとに別トークン
?width=2000 や ?size=Original を付けても、同じバイト数が返りました。imgix(?w=2000 のようなクエリ)や Cloudinary(/w_2000/ のようなパス)のようにURLで変形を指定するパラメトリックな方式ではなく、サイズごとに別トークンを持つ設計のようです。
詳細ページの DOM を見ると、各ビューが3つのトークンを持っていました。
| レンディション | 取得元 | サイズ(同一画像で実測) |
|---|---|---|
| thumb | サムネ列の img@src | 約 5 KB |
| preview | div[data-preview-url] | 約 132 KB |
| zoom | div[data-zoom-url] | 約 5.78 MB |
URLでサイズを変えるのではなく、欲しいサイズのトークンを HTML から拾う形です。失効はトークン側ではなく Fastly の purge で行う運用とみられます。
その作品自身の画像に絞る
詳細ページには関連作品のサムネも多く含まれます(1ページで100トークンを超えました)。作品自身のメディアは div#carousel-node-<id> の中にあり、この <id> は API の id フィールドと一致していました。
const carousel = doc.querySelector('[id^="carousel-node-"]'); // 自身のメディアのみ
const cdn = t => `https://<alias>.cdn.picturepark.com/v/${t}/`;
const views = [...carousel.querySelectorAll('[data-zoom-url]')].map(el => ({
zoom: cdn(el.getAttribute('data-zoom-url').match(/\/v\/([A-Za-z0-9]+)/)[1]),
preview: cdn(el.getAttribute('data-preview-url').match(/\/v\/([A-Za-z0-9]+)/)[1]),
}));
これで「ID → そのビューごとのURL」が得られます。
全件取得の可否
コレクション検索UIの表示では総数が10万点を超えるとされ、そのうちオンラインで閲覧できるのは8万点規模と表示されていました。全件取得を考えると、技術面とポリシー面の双方に制約がありました。
技術面:全件を列挙する手段
- 検索語を与えない場合は既定の10件が返り、全件を一度に返すクエリは見つかりませんでした(語によっては0件のこともありました)
- ファセット絞り込みのパラメータ(
type=/f[0]=等)は API では効かないようでした /sitemap.xml、/jsonapi、/api、/rest/session/tokenはいずれも 404 で、Drupal ではあるものの標準のデータ出口は公開されている範囲では無効化されているようです- ページ送り自体は深く効きました(ある語で60ページ・600件を超えても上限には当たりませんでした)が、与えた語にマッチする物しか辿れません
調査した限り、全件をカバーするには「語の辞書で総当たりして id で重複排除する」ような方法しか見当たらず、網羅性を保証する手段は見つかりませんでした。
ポリシー面:robots.txt の記述
User-agent: *
Content-Signal: search=yes, ai-train=no # AI学習目的の収集は対象外(EU DSM指令4条の権利留保として記載)
Crawl-delay: 10
Disallow: /collection # 詳細ページ・検索が Disallow 対象
Disallow: /site-search
User-agent: ClaudeBot Disallow: /
User-agent: GPTBot Disallow: /
User-agent: CCBot Disallow: /
# Amazonbot, Google-Extended, meta-externalagent などAI関連クローラも同様
画像URLの抽出に必要な詳細ページのパスは、robots.txt で Disallow 対象に含まれています。加えて Crawl-delay: 10 が指定されています。
一方で、メタデータの API エンドポイントは Disallow には含まれておらず、運営者自身も自由な利用を案内しています。整理すると次のようになります。
| 目的 | 可否 |
|---|---|
| メタデータ(個別・少量) | API で取得可(公認) |
| メタデータ全件 | 語の総当たりで近似可・網羅は保証できず |
| 画像URL一覧(全件) | 詳細ページ取得が必要で、robots.txt で Disallow 対象 |
調査からの所感
技術的には詳細ページから画像URLを取り出せることは確認できましたが、robots.txt が詳細ページを Disallow 対象としているため、規約の趣旨を尊重して全件の自動収集は採用していません。API が正規ルートで、本記事の詳細ページ側の手法は構成を説明するためのものです。全件のデータが必要であれば、収集ではなく運営者へ直接データ提供を相談する方法が考えられます。
調査を通じて確認できたのは次の点です。
- 画像を公開していることと、画像URLを機械可読に提供していることは別だった。メタデータ API は公開されている一方、画像URLは API には載らず、HTML 内の DAM トークンとして持っていた
- Cloudflare Bot Fight Mode は、クッキーではなくフィンガープリントで判定する場合がある。
cf_clearanceを取得して使い回す方法が効かず、実ブラウザが必要になる場面があった - オープンデータを掲げる組織でも robots.txt の確認は必要だった。近年は
Content-Signal(収集可否シグナル)や AI 関連クローラの個別 Disallow が増えており、「公開」と「収集してよい」が区別されてきている
「公開されているか」「APIで取得できるか」「取得してよいか」は、それぞれ別の問いでした。
本記事の調査は技術的検証を目的としたもので、対象サイトの robots.txt の方針を尊重し、全件取得・データセット化は行っていません。対象の識別子は伏せ字にしています。
コメント
…