概要
NDL-DocLデータセットとYOLOv5を用いたレイアウト抽出モデルを作成しました。
GitHub - ndl-lab/layout-dataset: NDL-DocLデータセット(資料画像レイアウトデータセット)
NDL-DocLデータセット(資料画像レイアウトデータセット). Contribute to ndl-lab/layout-dataset development by creating an account on GitHub.
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
本モデルは以下のノートブックからお試しいただけます。
本記事は、上記の学習過程の備忘録です。
データセットの作成
Pascal VOC形式のNDL-DocLデータセットを、YOLO形式に変換します。この方法については、以下の記事を参考にします。Pascal VOC形式からCOCO形式への変換に加えて、COCO形式からYOLO形式への変換を追加しています。
NDL-DocLデータセット(資料画像レイアウトデータセット)の変換と可視化
NDL-DocLデータセット(資料画像レイアウトデータセット)の変換と可視化
学習
以下のページにカスタムデータの学習方法が記載されています。
Train Custom Data
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov5 development by creating an account on GitHub.
以下のノートブックにも学習方法が記載されています。

Google Colab
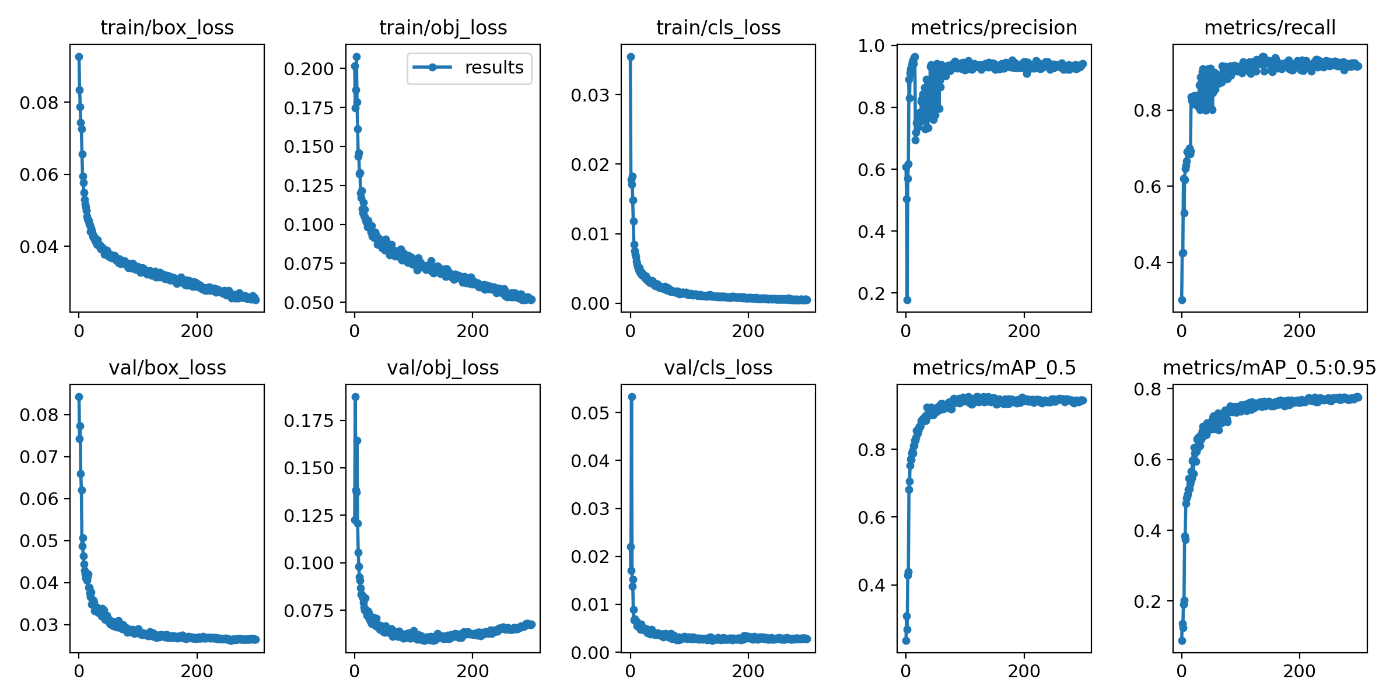
入力画像のサイズを1024、バッチサイズを4、エポック数を300に設定した結果、以下のような結果が得られました。なお、データセットをtrain 80%, validation 10%, test 10%に分けています。
推論
上述した通り、以下のノートブックから推論をお試しいただけます。
以下、推論結果の例です。うまく認識できた例のみを掲載しています。
『源氏物語』(東京大学所蔵)

『源氏物語』(京都大学所蔵)

『源氏物語』(九州大学所蔵)

まとめ
レイアウト認識の結果を踏まえ、次は行内の文字認識に取り組みたいと思います。
動画版(生成AIによる自動生成): この記事の内容をずんだもん×四国めたんの掛け合いで解説しています。自動生成のため、内容に誤りがある可能性があります。正確な情報は記事本文をご参照ください。


コメント
…