TEIとXML入門 ― 人文学テキストを「データ」にする
人文学のテキストを構造化して扱う国際標準 TEI と、その土台となる XML を、初学者向けに概念から解説します。CC ライセンスのオープン教材を参照した独自構成・実験的な取り組みです。
掛け合い解説(ずんだもん×四国めたん)
別バージョン
ナレーション解説
章立て
- 1
本編
TEIとXMLの考え方・ヘッダと本文・なぜ標準・符号化は解釈・始め方
読み上げ原稿
- 0:00人文学テキストを「データ」にする
皆さん、こんにちは。デジタル・ヒューマニティーズ入門、技術要素シリーズを担当します、なかむらさとるです。デジタル・ヒューマニティーズ、略して、DHは、コンピュータを使って、人文学の研究を、新しいやり方で、進めていく試みです。この回のテーマは、TEIと、XMLです。人文学のテキストを、コンピュータでも扱える「データ」にする、その考え方を、初学者向けに、図を交えながら、ゆっくり見ていきます。プログラミングの予備知識は、なくても、大丈夫です。コードも、ほとんど書きません。どうぞ、気楽について来てください。

- 0:46この動画について
はじめに、この動画について、簡単に、ご案内します。この動画は、クリエイティブ・コモンズ(CC)で、公開されている、オープンな教材を、参照しつつ、独自に、構成した、解説です。スライドと、図は、新規に作成し、ナレーションは、本人の声をもとにした、AIの、音声合成で、つくっています。あくまで、実験的な、取り組みですので、内容は、ご確認・ご注意のうえ、ご利用ください。もし、誤りに、気づかれたら、概要欄から、ご指摘いただけると、たすかります。出典と、ライセンスは、動画の最後と、概要欄に、まとめてあります。それでは、本編に、入りましょう。

- 1:38この回のゴール
まず、この回のゴールを、確認しておきましょう。目標は、大きく、四つです。一つめは、TEIと、XMLが、テキストの、何を記述する仕組みなのかを、自分の言葉で、説明できること。二つめは、要素、属性、入れ子、という、基本の組み立てを、読めるようになること。三つめは、ヘッダと、本文の、役割の違いが、分かること。そして四つめは、符号化、つまり、テキストに印をつける作業が、解釈をともなう行為だと、説明できることです。少し、耳なれない言葉も、出てきますが、一つずつ、ほどいていきますので、この四つを、頭の片隅に置いて、聞いてください。

- 2:32今日の流れ
今日の流れを、ざっと、ご紹介します。はじめに、テキストを「データ」にするとは、どういうことかを、XMLの考え方から、見ていきます。つぎに、TEIとは、何か。それから、なぜ、わざわざ「標準」を使うのか、そして、どんな場面で使われているか。続いて、符号化は「解釈」である、という、少し踏み込んだ話。最後に、自分で始めるための、手がかりを、紹介します。

- 3:08テキストを「データ」にするとは
それでは、さっそく、はじめましょう。まずは、テキストを「データ」にする、とは、いったい、どういうことなのか。なるべく、身近なところから、出発して、XMLの、考え方へと、少しずつ、進んでいきます。

- 3:27一文の中には、いくつもの情報がある
図を、見てください。たとえば、ここに、こんな一文が、あったとします。ある人物が、ある場所で、ある時代に、生まれた、という、ごく短い文です。私たちが、この文を読むとき、頭の中では、ここは人の名前、ここは土地の名前、ここは年代、というふうに、いくつもの種類の情報を、ほとんど一瞬で、しかも、自然に、見分けています。ふだんは、まったく意識しませんが、一見すると、ただの、文字の並びにしか見えない一文の中にも、じつは、人名、地名、年代といった、いくつもの情報が、層のように、重なって、ひそんでいるのです。そして、その、重なった情報こそが、私たちが、ふだん、読み取っている、意味の、正体だ、ともいえます。
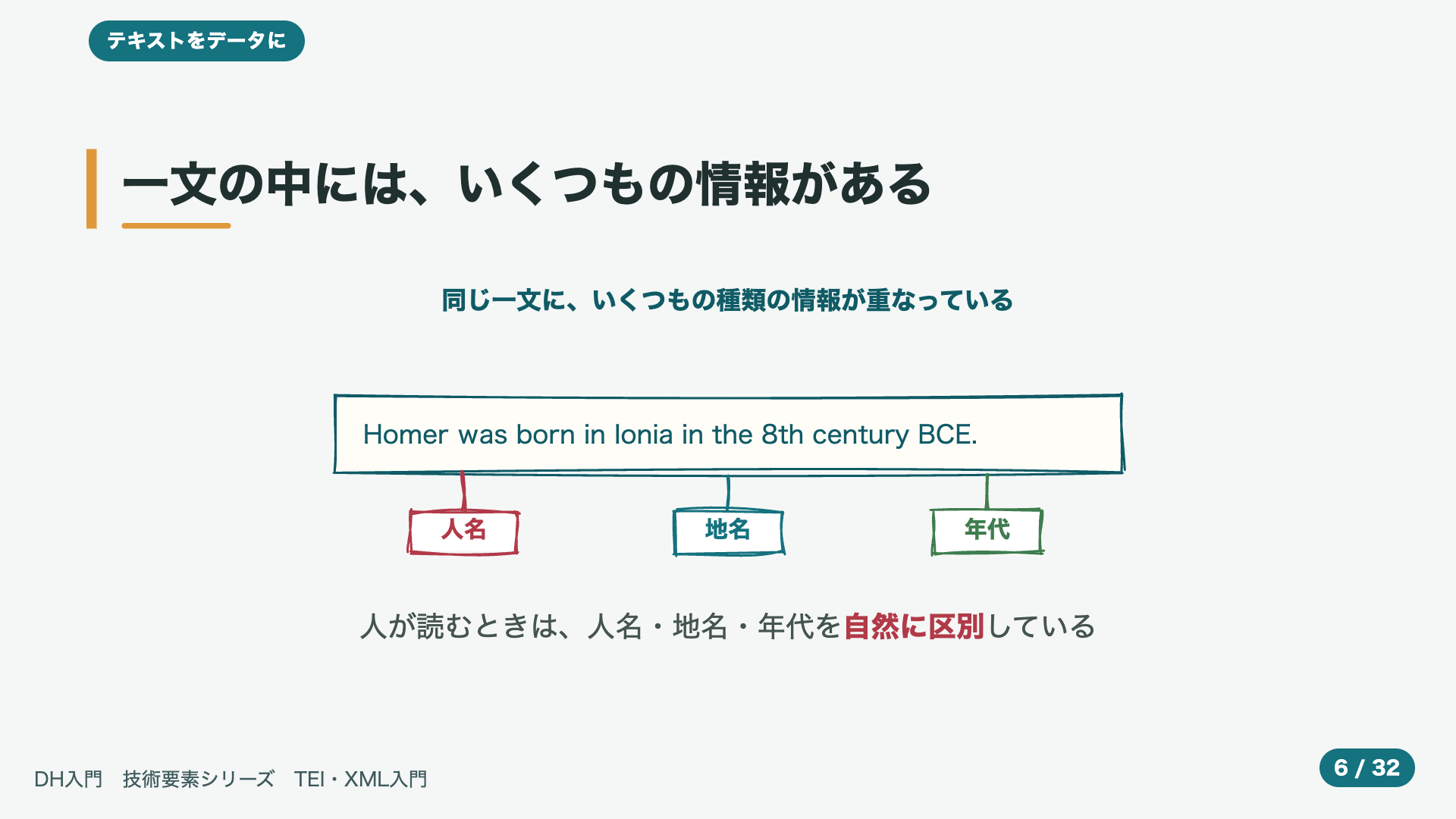
- 4:27人は読んで区別できる。では機械は?
では、この同じ文を、機械に渡すと、どうなるでしょうか。私たち人間は、ホメロスを人名、イオニアを地名と、ほとんど無意識に、見分けます。たとえ、知らない名前でも、文のかたちや、前後の流れから、これは人らしい、これは場所らしい、と、見当を、つけられます。けれど、ただの、文字の並びを、渡された機械には、その区別は、まったく、見えていません。どこからどこまでが、ひとつの人名なのかさえ、分からないのです。だからこそ、ここは人名、ここは年代、というふうに、人間の側から、あらかじめ、印をつけて、教えてあげる必要が、出てくるのです。いわば、人の頭の中にある、暗黙の区別を、外に、書き出してあげる、ということです。

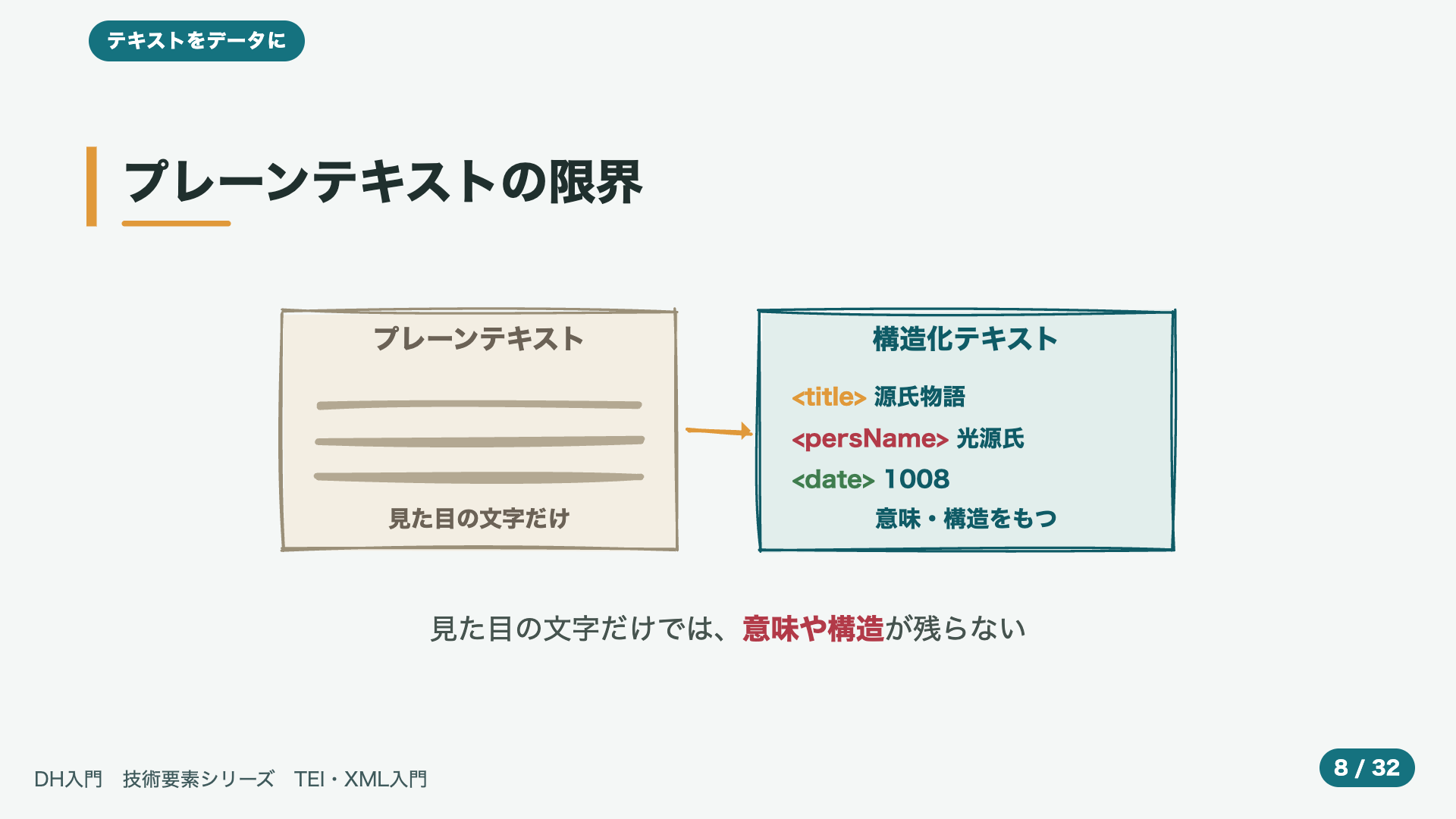
- 5:26プレーンテキストの限界
図の、左を、見てください。ふだん、私たちが、目にするテキスト、いわゆる、プレーンテキストは、見た目の文字を、ただ、順番に、並べたものです。人が、読むぶんには、それで、まったく、困りません。けれど、そこには、どれが題名で、どれが人名なのか、といった、意味や、構造の情報は、ほとんど、残っていないのです。一方、右のように、ここは題名、ここは人名、ここは日付、という印を、つけておくと、どうでしょう。その文章が、どんな意味の、どんな構造を、持っているのかを、あとからでも、機械が、正確に、たどれるように、なります。この、残るか、残らないか、の違いが、今日の話の、出発点です。印をつける、ということは、人の読み取りを、その場かぎりにせず、データとして、残しておくこと、だとも、いえます。
- 6:41マークアップ=意味に「タグ」を付ける
この、印を、つけていく作業のことを、マークアップと呼びます。じつは、マークアップには、文字の、見た目を、指示するものも、ありますが、ここで、大事なのは、これは人名、これは書名、というふうに、意味や、構造を、示すタイプ、いわゆる、記述的マークアップ、です。TEIが、使うのも、こちらです。図を、見てください。ある語の、前と、後ろを、タグと呼ばれる、目印で、はさみこみ、ここからここまでは人名です、と、文章の中に、書き込んでいきます。難しそうに、聞こえるかもしれませんが、やっていることは、紙の文章に、色ペンで、線を引いたり、付箋を、貼ったりするのと、とても、よく似ています。ちがいは、その線や、付箋を、機械にも、読み取れるように、決まった形で、付ける、という点だけです。

- 7:54XMLの基本① 要素とタグ
その、マークアップを、書くための、世界共通の、代表的なルールが、XMLです。図の、例を、見てください。まず、内容の、始まりを示す、開始タグ。そして、終わりを示す、終了タグ。この二つで、中身を、はさみます。この、はさまれた、ひとまとまり全体を、要素、と呼びます。ここでは、人名を表す、パーソンネーム、という名前のタグで、ホメロス、という語を、はさんでいます。たった、これだけのことで、この部分は、まちがいなく人名だ、ということが、人間にも、そして、機械にも、はっきりと、伝わるように、なるのです。なお、終了タグの、先頭には、斜めの線が、つきます。これが、開始タグとの、見分けの目印です。

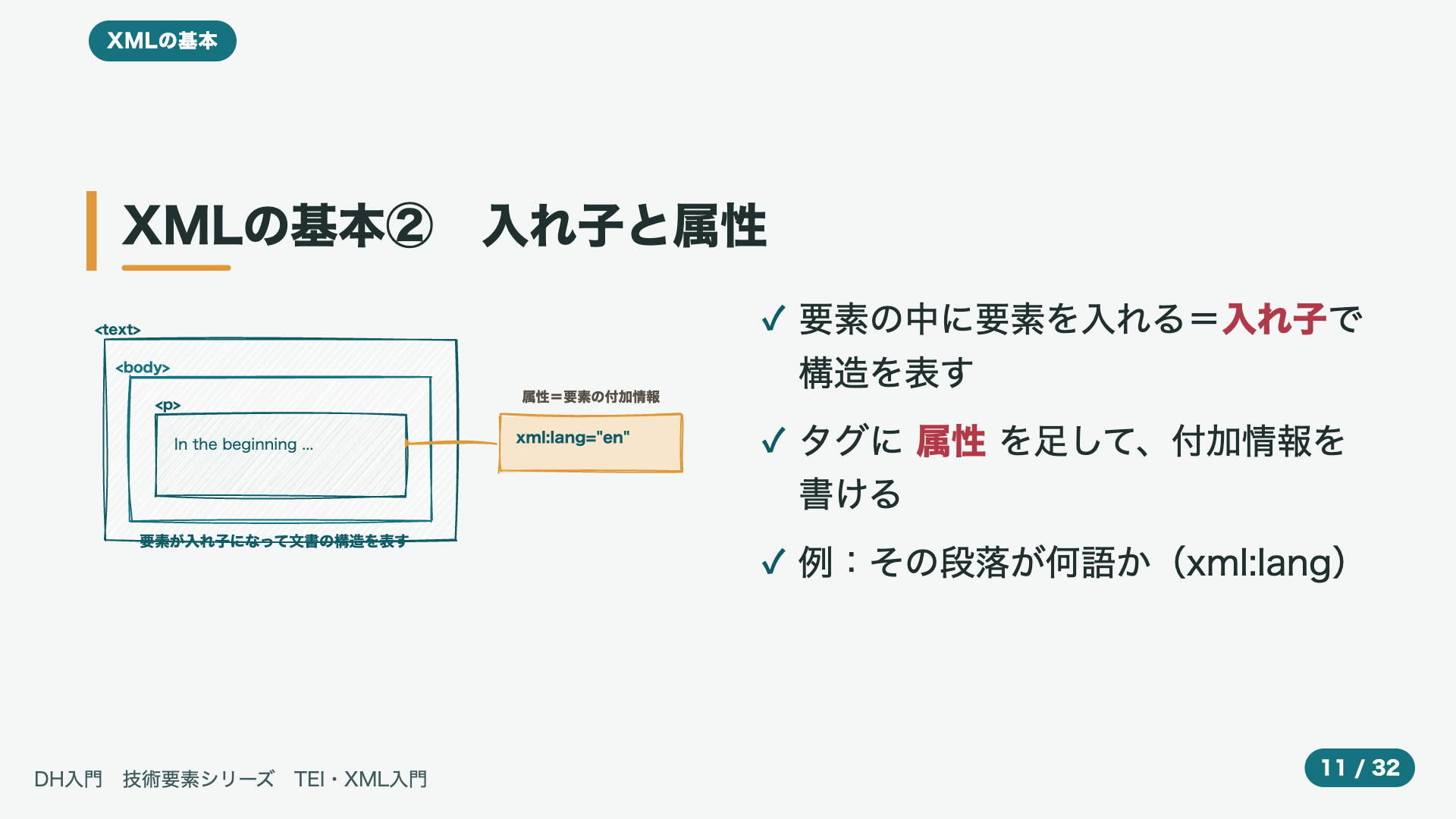
- 9:02XMLの基本② 入れ子と属性
XMLには、もう二つ、ぜひ、覚えておきたい、仕組みが、あります。図を、見てください。一つめは、入れ子、です。要素の中に、さらに、別の要素を、入れることが、できます。こうすることで、たとえば、本、という大きなまとまりの中に、章があり、その章の中に、段落がある、といった、文書全体の、入り組んだ構造を、そのまま、写しとることが、できます。二つめは、属性、です。タグに、ちょっとした、付け足しの情報を、添えることが、できます。たとえば、この段落は、英語で書かれている、といったことを、タグの中に、書き込んでおく、という具合です。入れ子で、おおきな構造を、属性で、こまかな情報を。この二つで、表現できることの幅が、ぐっと、広がります。
- 10:16ここまでのポイント
ここで、いったん、整理しておきましょう。一つ、テキストには、見た目の裏に、人名や、構造といった、いろいろな情報が、含まれている。二つ、それを、機械にも分かる形にするのが、マークアップ。三つ、XMLは、要素、入れ子、属性という、部品で、その構造を、書き表す、書き方でした。では、人文学のテキストには、いったい、どんなタグを、使えばいいのでしょうか。その答えを、用意してくれるのが、TEIです。

- 11:03TEIとは
さて、XMLという、土台を、つかんだところで、いよいよ、本題に、入ります。ここからは、TEIとは、いったい、何なのかを、見ていきましょう。

- 11:18TEI=人文学テキスト符号化の国際標準
TEIは、テキスト・エンコーディング・イニシアティブ、という言葉の、頭文字を、とったものです。日本語にすると、テキストの符号化のための、共同の取り組み、といった、意味あいに、なります。さきほど、XMLという、書き方を、学びましたが、では、人文学のテキストには、具体的に、どんな名前のタグを、どんなふうに、使えばいいのか。その、こまかな取り決めを、国際的に、定めたものが、TEIです。そして、これは、単なる、ルール集、というだけでは、ありません。それを、長年にわたって、支え、育ててきた、世界じゅうの研究者の、コミュニティの、名前でも、あるのです。

- 12:16背景:研究者たちが育ててきた標準
少し、その背景にも、触れておきましょう。TEIは、千九百八十七年に、国境を越えた、研究者たちの、共同の取り組みとして、産声を上げました。もう、四十年近く、続いている、ということに、なります。それ以来、世界中の、研究者や、図書館が、いったい、何を、どのように、記述すべきなのかを、長い時間をかけて、議論し、少しずつ、改訂を、重ねてきました。いま、もっとも広く、使われているのは、第五版、P5と呼ばれる、版です。一人の発明、というよりも、多くの人の手で、育てられてきた、標準だと、いえます。

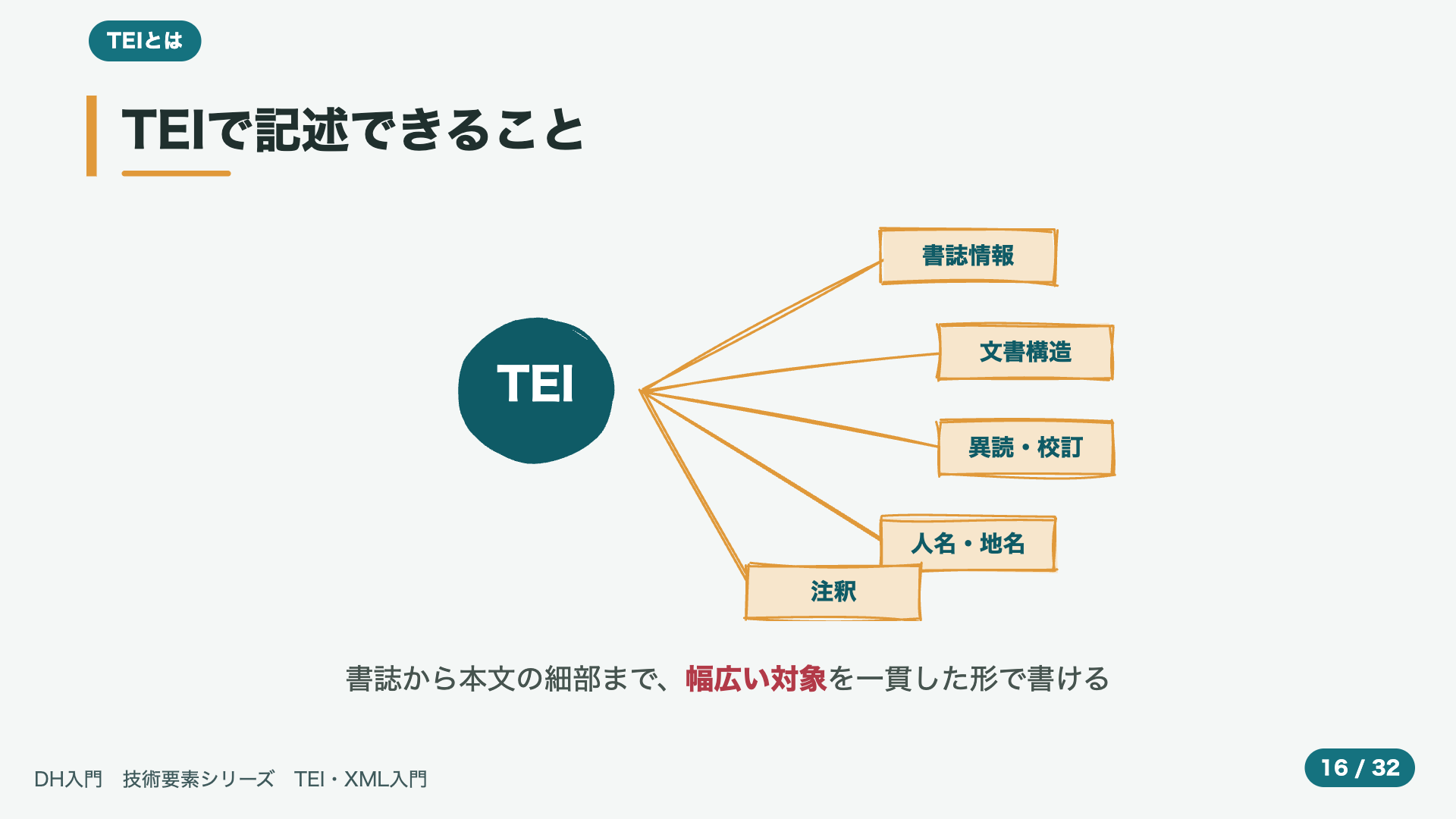
- 13:09TEIで記述できること
では、TEIで、いったい、どんなことが、記述できるのでしょうか。図を、見てください。その範囲は、思いのほか、広いものです。たとえば、本の、タイトルや、著者といった、書誌の、情報。段落や、章といった、文書の、構造。さらに、同じ作品でも、写本によって、本文が、少しずつ、違っていることが、ありますが、その、こまかな違い、いわゆる、異読。そして、人名や、地名、注釈まで。文学作品から、歴史の、文書まで、こうした、さまざまな対象を、人それぞれの、自己流ではなく、共通の、一貫した形で、書きあらわしていくことが、できるのです。逆に言えば、何を、記述したいかに応じて、用意された、たくさんのタグの中から、必要なものを、選んで、使っていく、ということです。
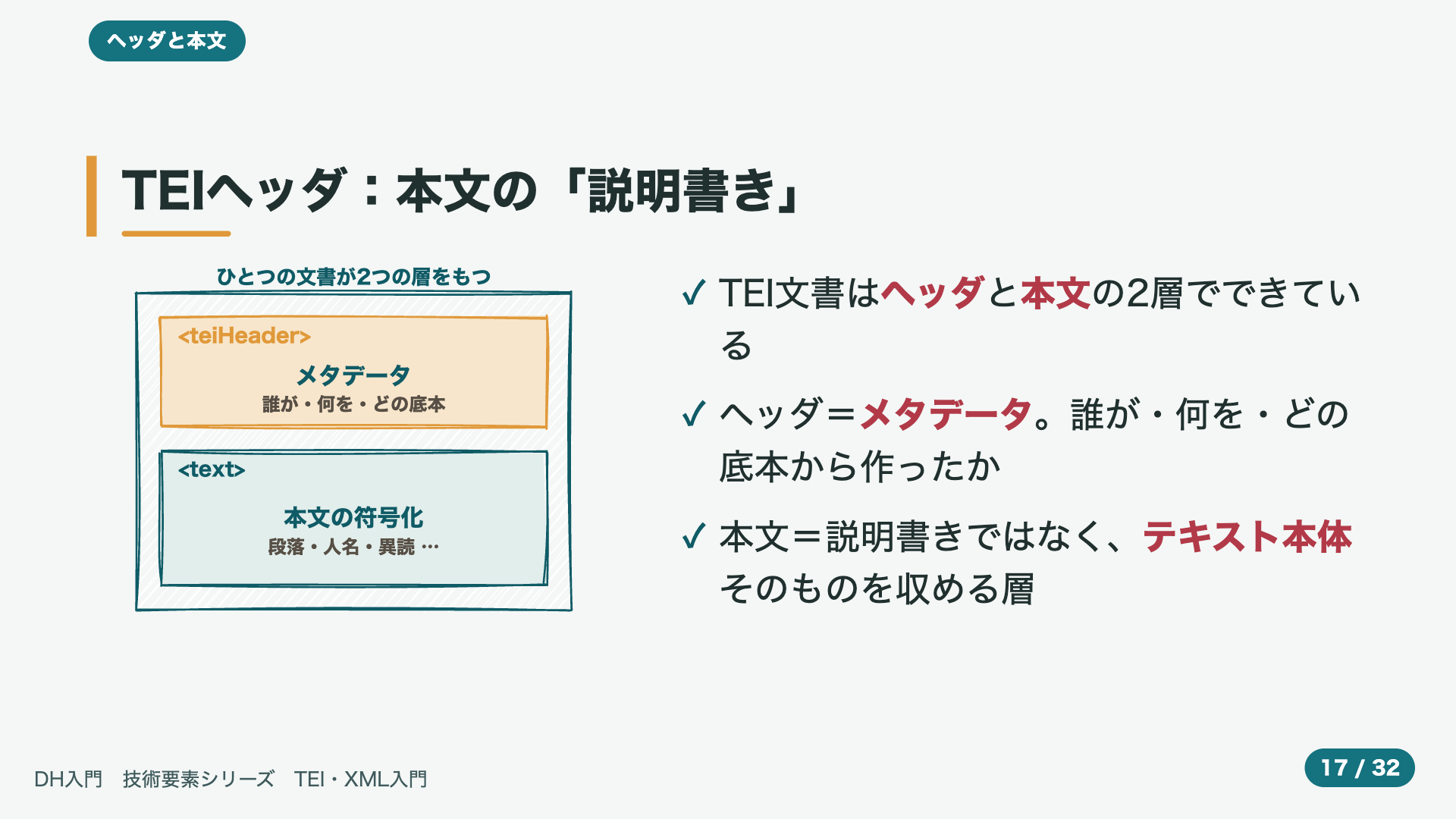
- 14:19TEIヘッダ:本文の「説明書き」
TEIの文書は、図のように、大きく、二つの層から、できています。一つめは、ヘッダ、と呼ばれる部分です。これは、その資料についての、メタデータ、いわば、表紙の裏に書かれた、説明書きに、あたります。この資料は、いったい、誰が、何という作品を、どの本を、ていほんとして、作ったのか。そうした情報を、ここに、まとめて、記します。そして、二つめが、本文です。こちらは、説明書きではなく、作品の、テキスト本体そのものを、収める層です。詩でも、小説でも、その中身を、ここに置いて、構造や、人名などの、タグを、付けていきます。タグを付ける、という点では、ヘッダも、本文も、同じですが、ヘッダが、資料についての、情報なのに対して、本文は、テキスト、そのものです。この、二つの層に、分かれている、おかげで、たとえば、本文だけを、取り出して、分析する、といったことも、たやすく、できます。
- 15:39本文を符号化してみる
では、本文を、実際に、符号化してみると、どうなるか。図の、例を、見てください。まず、段落、全体を、ピー、という、短いタグで、すっぽりと、はさんでいます。そして、その内側で、人名を表すタグで、ホメロスを、地名を表すタグで、イオニアを、それぞれ、囲っています。たった、これだけの、ごく短い例ですが、もう、どこからどこまでが、ひとつの段落で、その中の、どれが、人名で、どれが、地名なのかが、ひと目で、そして、機械にとっても、はっきりと、区別できる形に、なっています。

- 16:27例を読み解く
もう少し、この例を、ていねいに、読み解いてみましょう。いちばん外側にある、段落を表すタグ、その、はじまりと、終わりが、ひとつの段落の、範囲を、はさんで、示しています。そして、その内側に、人名のタグと、地名のタグが、あって、それぞれ、対応する語を、指し示しています。こうして、印を、つけておくと、どうなるか。たとえば、この資料の中から、人名だけを、もれなく、集めてくる。あるいは、出てきた地名を、ぜんぶ、地図の上に、並べてみる。そういったことが、人手をかけずに、機械の力で、できるように、なるのです。一件ずつ、手で、拾っていく、手間を、思えば、この差は、とても、大きなものです。

- 17:26考えてみよう
ここで、少し、立ち止まって、考えてみましょう。あなたが、ふだん、扱っている資料なら、いったい、どこに、タグを、付けてみたいでしょうか。人名でしょうか。日付でしょうか。それとも、地名や、引用でしょうか。よろしければ、ここで一度、動画を止めて、ご自分の資料を、思い浮かべてみてください。

- 17:55ここまでのポイント
では、ここで、ふたたび、立ち止まって、整理しておきましょう。TEIは、人文学テキストのための、タグの、共通規格でした。そして、その文書は、資料の説明書きである、ヘッダと、実際に、タグを付けた、本文という、二つの層から、できあがっていました。段落や、人名、地名などに、印を、つけておけば、あとから、機械の力でも、扱えるようになる。ここまでが、TEIという仕組みの、いちばん、基本となる、考え方です。

- 18:36なぜ「標準」を使うのか
さて、ここで、ひとつ、素朴な疑問が、わいてきます。なぜ、自分の、好きなやり方ではなく、わざわざ、世界で、共通の「標準」に、合わせて、書くのでしょうか。その意味を、すこし、考えてみましょう。

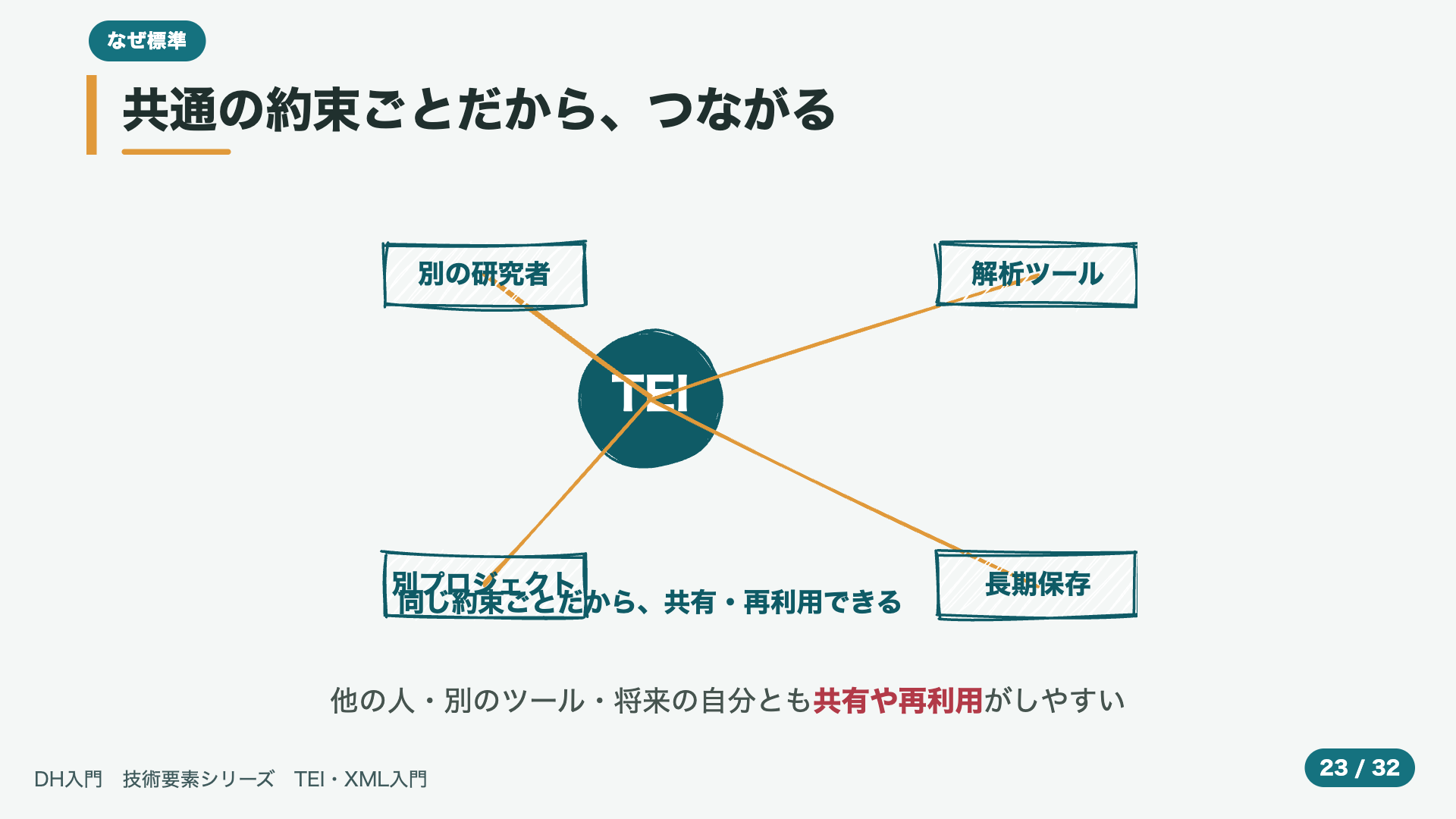
- 18:54共通の約束ごとだから、つながる
理由の、ひとつは、つながりやすさ、です。図を、見てください。みんなが、てんでに、自己流で書くのではなく、同じ約束ごとに、もとづいて、書いておくと、どうなるでしょう。すると、別の研究者や、データを、分析するための、さまざまな道具、あるいは、まったく別の、プロジェクト、さらには、何年か後の、自分自身とも、データを、共有したり、再利用したりが、ぐっと、しやすくなります。もし、一人ひとりが、ばらばらの、書き方を、していたら、せっかく作ったデータも、なかなか、つながりません。標準とは、いわば、みんなが、読み書きできる、共通の言葉、なのですね。いちど、その共通の言葉で、書いておけば、データの価値が、時間がたっても、目減りしにくい、というのも、大きな利点です。
- 19:53どこで使われているか
TEIは、けっして、机上の、決めごとでは、ありません。実際に、世界の、さまざまな場面で、使われています。図に、挙げたように、たとえば、研究のための、電子的な、校訂版。たとえば、図書館や、文書館などの、デジタルアーカイブ。あるいは、ぼうだいな量の、テキストを、集めて、分析する、コーパスの研究。研究者の、手元の、こまやかな仕事から、広く、一般に、公開される、大きな資料まで、本当に、はばひろい、場面で、活用されている、ということです。
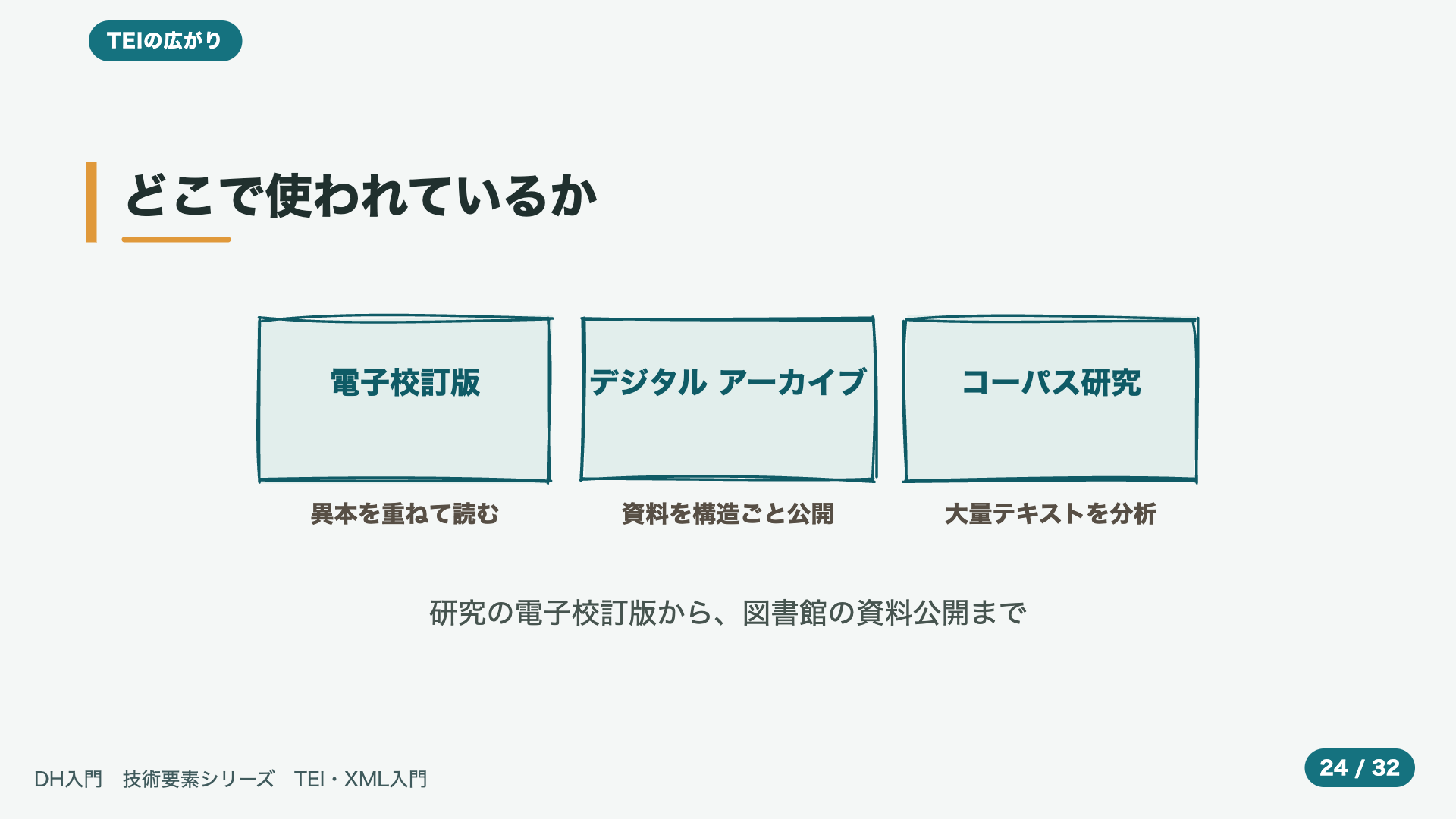
- 20:33たとえば、こんな使われ方
もう少し、具体的に、イメージを、ふくらませてみましょう。電子校訂版、というのは、たとえば、同じ作品の、いくつもの写本を、つきあわせて、本文の、こまかな違いを、重ね合わせ、画面の上で、読み比べられるように、したものです。デジタルアーカイブでは、貴重な、古典籍や、古文書を、ただの、画像としてではなく、その構造ごと、まるごと、検索できる形で、公開します。そして、コーパス研究では、何百、何千という、テキストを、語や、構造の、単位で、いちどに、まとめて、分析していきます。手作業では、とても、追いつかない規模です。そして、これらは、どれも、TEIという、共通の土台が、あればこそ、成り立っている、取り組みなのです。

- 21:27符号化は「解釈」である
そして、最後に、ぜひとも、お伝えして、おきたい、とても、大切な点が、あります。それは、符号化、つまり、テキストに、タグを付けるという作業が、じつは、ひとつの「解釈」なのだ、ということです。

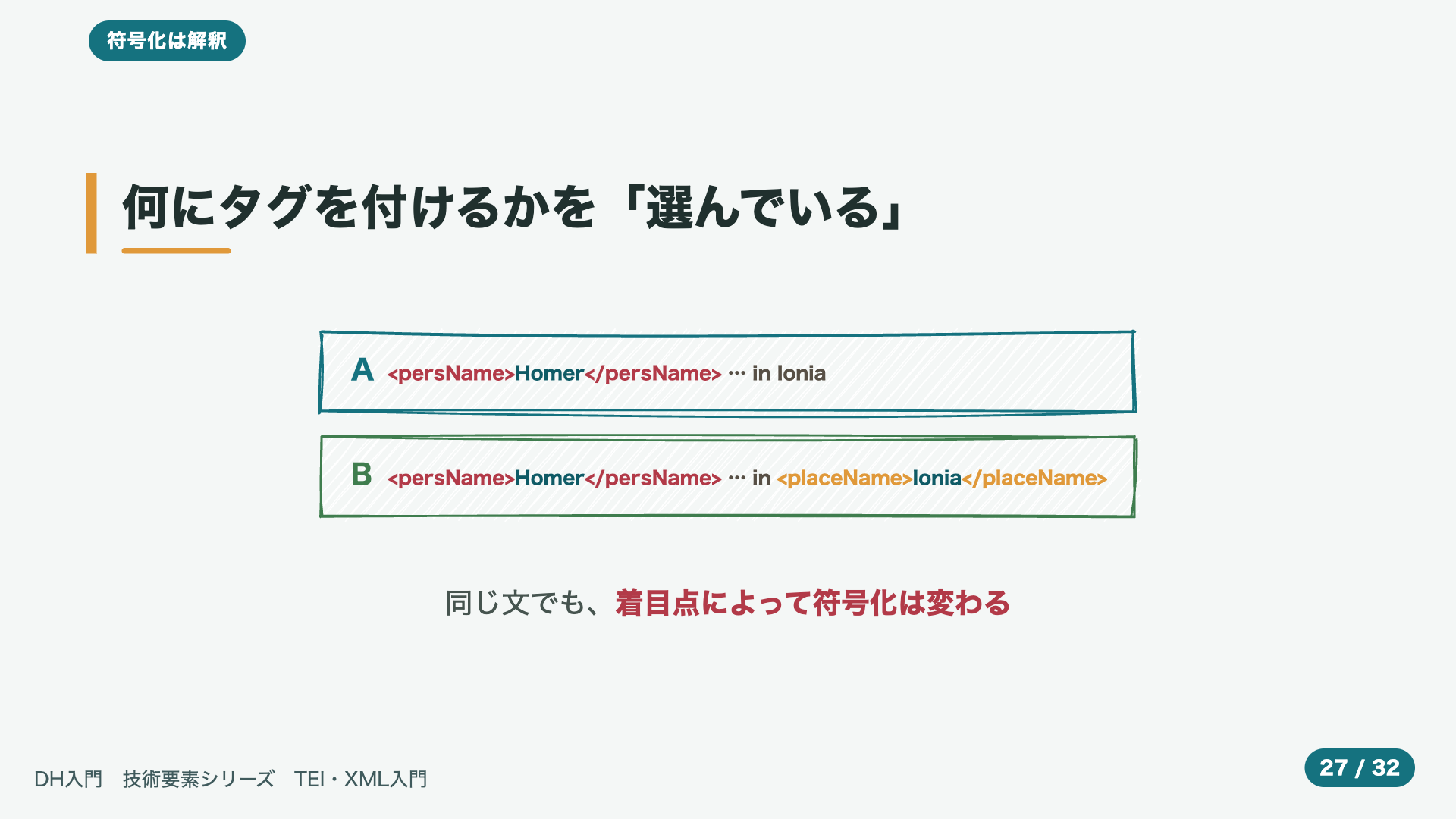
- 21:43何にタグを付けるかを「選んでいる」
図を、見てください。まったく、同じ、ひとつの文でも、上の、エーのように、人名だけに、タグを、付けることも、できますし、下の、ビーのように、人名と、地名の、両方に、付けることも、できます。さらに、年代にも、付けるかもしれません。そして、ここが、大事なところですが、このうち、どれか一つだけが、正しい、というわけでは、ありません。つまり、どこに、何として、印を、つけるのかは、そのつど、私たちが、選んでいるのです。同じ文を、前にしても、研究者が、何に、着目するかによって、出来上がってくる、符号化は、変わってくる、ということです。言いかえれば、ひとつの符号化には、その人の、読みの視点が、おのずと、映し出される、ということです。
- 22:40だから、唯一の正解は決まらない
ということは、ここには、ただ一つの、正解が、はじめから、決まっている、というわけでは、ありません。どこを、何として、印づけるか、その判断には、どうしても、その人の、研究上の、ものの見方が、入ってきます。でも、これは、けっして、弱点では、ありません。むしろ、自分が、そのテキストを、どう読んだのか、という解釈を、目に見える形にして、はっきりと、示せる。そう考えると、これは、大きな、強みでも、あります。符号化は、一見、機械的な、単純作業のように見えて、じつは、すぐれて、人文学的な、いとなみ、なのです。

- 23:29始め方・学ぶには
では、自分でも、少し、始めてみたい、と思ったら、どうすれば、よいでしょう。まず、文書を、書いたり、編集したりするには、有償の、XML・エディタ、oXygenなどが、よく使われます。一方、自分用に、TEIを、仕立てる、つまり、どのタグを使うかという、カスタマイズを、作るには、ブラウザで、手軽に使える、無料の、ローマ、という、ツールが、あります。これは、文書を編集する道具ではなく、自分だけの、決まりを、組み立てるための、ものです。具体的な、例から、学びたいなら、TEI by Example、という、分野ごとに、分かれた、チュートリアルが、よい、手引きに、なります。もう少し、体系立てて、学びたい方には、DARIAH-Campusの、テキストエンコーディングの、講座が、おすすめです。そして、何より、まずは、ごく小さな、テキストを、一つ、選んで、自分の手で、タグを、付けてみること。それが、いちばんの、近道です。

- 24:38まとめ
今日の、まとめです。テキストを、見た目の文字から、構造をもった、データへと、変えていくのが、マークアップと、XMLでした。そして、TEIは、人文学テキストのための、タグの、国際的な、標準。文書は、説明書きである、ヘッダと、本文という、二つの層からなり、だからこそ、広く、共有や、再利用が、できるのでした。さらに、符号化は、何を印づけるかを、選ぶという、解釈をともなう、営みでもありました。テキストを、ただ読むだけでなく、構造として、捉えなおす。そんな視点を、ひとつ、手に入れた、と、いえるのではないでしょうか。

- 25:30出典・ライセンス
この動画は、海外で、オープンライセンスのもとに、公開されている、教材を、参照して、作成しました。主なものは、DARIAH-Campusの、テキストエンコーディングの、講座、TEIの、公式ガイドライン、そして、DARIAH-DEの、チュートリアルです。いずれも、クリエイティブ・コモンズ(CC)の、表示ライセンスで、公開されています。スライドと、図は、これらを、参考にしたうえで、あらためて、作り起こしたものです。

- 26:05ご清聴ありがとうございました
以上で、TEIと、XMLの、入門を、終わります。テキストを、データとして、捉えなおす。その第一歩を、つかんでいただけたなら、と思います。ご清聴、ありがとうございました。
